Large Language Models in Chemical Life Cycle Assessment: A New Frontier for Sustainable Drug Discovery
This article explores the transformative potential and practical challenges of integrating Large Language Models (LLMs) into Chemical Life Cycle Assessment (LCA) for researchers and drug development professionals.
Large Language Models in Chemical Life Cycle Assessment: A New Frontier for Sustainable Drug Discovery
Abstract
This article explores the transformative potential and practical challenges of integrating Large Language Models (LLMs) into Chemical Life Cycle Assessment (LCA) for researchers and drug development professionals. It provides a comprehensive examination, from foundational concepts where LLMs can automate data-intensive LCA tasks, to methodological applications in drug discovery pipelines like target identification. The content addresses critical troubleshooting for limitations such as model hallucinations and outlines optimization strategies. Finally, it presents a rigorous validation framework, benchmarking LLM performance against expert review to equip scientists with the knowledge to responsibly leverage AI for accelerating sustainable biomedical research.
LLMs and LCA: Demystifying the Core Concepts and Environmental Context
What are Large Language Models? A Primer on Transformers, Tokens, and Training
Large Language Models (LLMs) are a category of deep learning models trained on immense datasets, enabling them to understand, generate, and manipulate natural language with remarkable proficiency [1]. These models represent a significant leap in how humans interact with technology, as they are the first AI systems capable of handling unstructured human language at scale, moving beyond simple keyword matching to capture deeper context, nuance, and reasoning [1]. Their development is largely responsible for the recent explosion of artificial intelligence advancements and has become a cornerstone for various applications, including those in scientific domains such as chemical life cycle assessment (LCA) research. In LCA, LLMs offer the potential to automate the extraction and synthesis of chemical properties, environmental impact data, and regulatory information from vast scientific literatures, thereby accelerating sustainable drug development processes.
Foundational Architecture: The Transformer
At the heart of most modern LLMs lies the transformer architecture, introduced in the 2017 seminal paper "Attention Is All You Need" [2] [3]. This architecture overcame the limitations of previous recurrent neural networks (RNNs) and long short-term memory (LSTM) networks, which processed data sequentially and were difficult to parallelize [3]. The key innovation of the transformer is the self-attention mechanism, which allows the model to weigh the importance of different words in a sequence relative to each other, regardless of their positional distance [1] [2]. This parallel processing capability significantly reduces training time and allows models to handle long-range dependencies in text effectively [2].
The transformer architecture primarily consists of two components, though some models may use only one:
- Encoder: Processes the input sequence and builds a contextualized representation. It comprises multiple layers, each containing a multi-head self-attention mechanism and a feed-forward neural network [2] [4].
- Decoder: Generates the output sequence one token at a time, using information from the encoder and its own previous outputs. It includes an additional attention layer over the encoder's output compared to the encoder's structure [2].
The following diagram illustrates the flow of information through a standard transformer architecture:
The Self-Attention Mechanism
The self-attention mechanism is the centerpiece of the transformer [1]. It allows the model to flexibly focus on relevant context while ignoring less important tokens. For each token in a sequence, self-attention calculates a weighted sum of the values of all other tokens in the sequence, where the weights (attention scores) are determined by the compatibility between the token's query and the keys of all other tokens [1]. This process enables the model to understand contextual relationships, such as resolving pronoun antecedents (e.g., knowing whether "it" refers to "the animal" or "the street" in a sentence) [4].
Core Components and Protocols
Tokenization: The Input Protocol
Tokenization is the foundational process of converting raw text into a format understandable by an LLM. It breaks down text into smaller, manageable units called tokens, which can be whole words, subwords, or characters [5] [6]. This process is crucial for models to handle rare words, typos, and multilingual text efficiently [6].
Workflow Protocol: The tokenization process follows a standardized, multi-step protocol:
- Step 1: Normalization: The input text is converted into a standard, machine-friendly form. This includes converting characters to lowercase, applying Unicode normalization, and trimming extra whitespace [5].
- Step 2: Pre-tokenization: The normalized text is broken into preliminary chunks based on spaces and punctuation [5]. For example, "Let's explore!" might become
["Let", "'", "s", "explore", "!"]. - Step 3: Subword Segmentation: The chunks are further broken down into meaningful subword units using algorithms like Byte Pair Encoding (BPE) or WordPiece [5] [7]. This allows the model to process uncommon words (e.g., "unstoppable" →
["un", "stop", "able"]) [5]. - Step 4: Mapping to IDs: Each resulting token is mapped to a unique integer ID from the model's predefined vocabulary, which is fixed after training [5] [7]. Special tokens (e.g., beginning-of-sentence, end-of-sentence) are also added to manage sequence boundaries [5].
Table 1: Common Tokenization Algorithms and Their Characteristics
| Algorithm | Mechanism | Example Model Usage | Handling of 'unstoppable' |
|---|---|---|---|
| Byte Pair Encoding (BPE) [5] | Iteratively merges the most frequent pairs of characters or bytes. | GPT series [5] [7] | ["un", "stop", "able"] |
| WordPiece [5] | Merges subwords based on probability, not just frequency. | BERT [5] | ["un", "stop", "##able"] |
| Unigram [5] | Uses a probabilistic model to iteratively remove the least valuable tokens. | ["un", "stop", "p", "able"] |
Model Training Pipeline
The development of a sophisticated LLM is a multi-stage process designed to first instill broad knowledge and then refine the model's behavior for specific tasks or alignment with human preferences.
Protocol 1: Pretraining
- Objective: To build a base model (or foundation model) with general-world knowledge and language understanding by learning to predict the next token in a sequence [1] [8].
- Method: Self-supervised learning on a massive corpus of raw, unlabeled text (e.g., web pages, books, code) [1] [8]. The model adjusts its internal parameters (weights) through trillions of examples to minimize the error in its predictions, a process involving backpropagation and gradient descent [1].
- Output: A base model capable of next-token prediction but not yet refined for specific tasks like instruction following [8].
Protocol 2: Post-Training (Fine-Tuning and Alignment)
- A. Supervised Fine-Tuning (SFT)
- Objective: To adapt the base model to perform specific tasks or follow instructions [1] [8].
- Method: Training the model on a smaller, high-quality dataset of (input, output) pairs that demonstrate the desired task, such as question-answering or summarization [1]. This updates the model's weights to produce outputs closer to the human-provided examples.
- B. Reinforcement Learning from Human Feedback (RLHF)
- Objective: To further align the model's outputs with human preferences for qualities like helpfulness, safety, and style [1] [8].
- Method: Humans rank different model outputs, and a reward model is trained to predict these rankings. The LLM is then fine-tuned using reinforcement learning to maximize the reward, encouraging it to generate outputs that humans prefer [1].
Table 2: Key Concepts in LLM Operation and Deployment
| Concept | Description | Implication for Researchers |
|---|---|---|
| Inference [1] | The process where a trained model generates output for a given prompt, one token at a time. | The core operation for using an LLM in an application. |
| Context Window [1] [6] | The maximum number of tokens a model can process in a single interaction. It is the model's "short-term memory." | Limits the amount of text (e.g., a research paper, a long conversation) that can be processed at once. |
| Retrieval-Augmented Generation (RAG) [1] | A technique that connects an LLM to external knowledge bases, providing it with relevant, up-to-date information during inference. | Crucial for overcoming knowledge cut-offs and grounding model responses in specific, factual data (e.g., proprietary chemical databases). |
The Scientist's Toolkit: Essential Research Reagents for LLM Experimentation
Table 3: Key "Research Reagent Solutions" for LLM Application Development
| Tool / Component | Function / Protocol | Relevance to Chemical LCA Research |
|---|---|---|
| Tokenizer [5] [7] | Converts raw text to token IDs and back. Different models (GPT, BERT) use different tokenizers. | Essential for preprocessing scientific literature, patents, and chemical data sheets before analysis by an LLM. |
| Base Model (e.g., LLaMA, GPT) [1] [9] | A pretrained, general-purpose LLM. Serves as the foundation for task-specific customization. | The starting point for building a domain-specific assistant for life cycle assessment without the prohibitive cost of pretraining. |
| Instruction-Tuned Model [1] | A model fine-tuned to follow user instructions and engage in conversation. | Ready-to-use for Q&A and summarization tasks (e.g., "Summarize the environmental impact of this solvent."). |
| Embedding Model [9] [2] | Converts text into numerical vectors (embeddings) that capture semantic meaning. | Enables semantic search across scientific corpora to find relevant studies based on meaning, not just keywords. |
| RAG Pipeline [1] | A system architecture that retrieves documents from a knowledge base and feeds them to an LLM to generate answers. | Allows an LLM to provide citations from trusted LCA databases and recent research, enhancing answer reliability. |
Application in Chemical Life Cycle Assessment Research
The technical components and protocols detailed above enable powerful applications of LLMs in chemical LCA and drug development. A primary use case is the automation of data extraction and synthesis. LLMs can be deployed to systematically scan and process vast scientific literature, technical datasheets, and regulatory documents to identify and extract key parameters relevant to LCA, such as energy consumption of synthesis pathways, greenhouse gas emissions, water usage, and toxicity profiles [1] [9]. Furthermore, through Retrieval-Augmented Generation (RAG), these models can be grounded in proprietary or highly specialized databases (e.g., Ecoinvent, PubChem), allowing researchers to build conversational interfaces that provide instant, cited answers to complex queries about chemical properties and their environmental impacts [1]. This capability significantly accelerates the early stages of drug development by providing rapid sustainability assessments, thereby fostering the design of greener pharmaceutical compounds and processes.
The Data-Intensive Challenge of Traditional Chemical Life Cycle Assessment
Life Cycle Assessment (LCA) has emerged as a critical tool for chemical companies under mounting pressure to reduce environmental impacts, comply with tightening regulations, and meet investor demands for clear sustainability strategies [10]. However, the application of traditional LCA to chemical products presents significant data-intensive challenges that complicate comprehensive environmental impact evaluation. The core of this challenge lies in the need for a comprehensive evaluation of a product's environmental footprint across its entire life cycle – from raw material extraction through production, use, and end-of-life phases [10].
The data requirements for credible chemical LCA are substantial, involving complex supply chains, multiple impact categories, and diverse geographical considerations. These requirements have become increasingly difficult to meet using traditional methodologies alone. Within this context, Large Language Models (LLMs) offer transformative potential to process, analyze, and generate insights from the vast datasets required for robust chemical LCA. The emergence of sophisticated LLM architectures and training approaches, including reinforced reasoning models and cultural learning-based adaptation frameworks, creates new opportunities to overcome longstanding bottlenecks in LCA data management and interpretation [11] [12].
The data-intensive nature of chemical LCA manifests across multiple dimensions, from supply chain complexity to regulatory requirements. The tables below summarize key quantitative challenges and the corresponding data management requirements.
Table 1: Core Data Challenges in Chemical Life Cycle Assessment
| Challenge Dimension | Specific Data Requirements | Traditional Limitations |
|---|---|---|
| Supply Chain Complexity | Data from multiple tiers of suppliers; upstream and downstream emissions tracking [10] | Limited supplier transparency; incomplete Scope 3 emissions data [10] |
| Impact Assessment | Multiple environmental impact categories (GHG emissions, water use, toxicity, etc.) [10] | Data gaps for less common impact categories; methodological inconsistencies |
| Geographical Variability | Region-specific data for energy grids, transportation, and resource availability [10] | Overreliance on global averages; lack of localized data for specific production regions |
| Temporal Dynamics | Time-sensitive data for energy sources, technological evolution, and policy changes | Static assessments that quickly become outdated; insufficient longitudinal tracking |
| Regulatory Compliance | Evidence for claims under EU CSRD, ESPR, Product Environmental Footprint (PEF) [10] | Difficulty substantiating green claims; compliance documentation burdens |
Table 2: Data Management Requirements for Credible Chemical LCA
| Data Management Aspect | Minimum Requirements | Advanced Capabilities Needed |
|---|---|---|
| Data Collection | Primary data for core processes; secondary data for background systems [10] | Automated data extraction from diverse formats (PDFs, spreadsheets, databases) |
| Data Quality | Evidence for data quality indicators (precision, completeness, representativeness) | Intelligent data gap filling with uncertainty quantification |
| Data Integration | Consistent formatting across multiple data sources | Semantic integration of disparate data structures and terminology |
| Data Transparency | Documented data sources and methodological choices | Full audit trails with provenance tracking and version control |
| Data Interpretation | Identification of environmental "hotspots" across life cycle stages [10] | Predictive modeling of improvement scenarios; strategic priority setting |
LLM-Enhanced Experimental Protocols for Chemical LCA
Protocol: Automated Data Extraction and Categorization from LCA Databases
Purpose: To systematically extract, classify, and structure unstructured LCA data using LLMs to overcome data fragmentation challenges.
Materials and Reagents:
- LLM Platform: Access to foundation models (e.g., GPT-4, Claude, or domain-specific models) [13]
- Data Sources: Scientific literature, regulatory documents, supplier environmental declarations [10]
- Computational Environment: Python/R environment with LLM API access or local model deployment
- Validation Datasets: Curated LCA databases (e.g., Ecoinvent, GLAD) for benchmarking [14]
Procedure:
- Data Collection: Compile heterogeneous data sources including PDF reports, spreadsheet inventories, journal articles, and supplier sustainability disclosures.
- Pre-processing: Convert all documents to standardized text format while preserving structural elements (tables, headings, units).
- LLM Fine-tuning: Adapt base LLM using LCA-specific terminology and methodologies through continued pre-training on curated corpora [13].
- Information Extraction: Implement structured prompting to extract key LCA parameters including:
- Inventory flows (inputs/outputs with quantities and units)
- Geographical and temporal scope information
- Methodological choices (allocation rules, impact assessment methods)
- Data quality indicators
- Cross-Validation: Compare LLM-extracted data with manual extractions on subset to calculate accuracy metrics.
- Data Integration: Transform extracted information into standardized LCA data format (e.g., ILCD, Ecospold) for model import.
Validation Metrics:
- Extraction accuracy (>95% for numerical parameters)
- Unit conversion precision (>99%)
- Completeness of dataset construction (>90% of required fields)
Protocol: Predictive Hotspot Identification Using Multi-Modal LLMs
Purpose: To leverage LLM reasoning capabilities for identifying environmental impact hotspots and improvement priorities across chemical product life cycles.
Materials and Reagents:
- Reasoning-Enhanced LLM: Models with reinforced reasoning capabilities (e.g., models trained with reinforcement learning for reasoning tasks) [11]
- LCA Inventory Database: Structured inventory data for chemical processes
- Impact Assessment Methods: Standardized characterization factors (e.g., TRACI, ReCiPe)
- Visualization Tools: Graph generation libraries for result communication
Procedure:
- Data Integration: Load complete LCA model with inventory and impact assessment results.
- Contextual Analysis: Apply LLM to analyze process metadata including:
- Technology maturity and scalability
- Economic considerations and cost data
- Regulatory constraints and drivers
- Stakeholder priorities and sustainability goals
- Pattern Recognition: Utilize LLM to identify unusual patterns or discrepancies in impact distributions across life cycle stages.
- Scenario Generation: Create alternative improvement scenarios based on hotspot analysis:
- Raw material substitution options
- Process optimization opportunities
- Energy efficiency improvements
- Circular economy strategies (recycling, recovery)
- Priority Ranking: Apply multi-criteria decision analysis with LLM-assisted weighting of environmental, economic, and technical factors.
- Recommendation Formulation: Generate actionable improvement strategies with estimated impact reduction potential and implementation considerations.
Validation Metrics:
- Alignment with expert hotspot identification (>90% concordance)
- Comprehensiveness of improvement opportunities identified
- Actionability of recommendations for decision-makers
Protocol: Regulatory Compliance and Reporting Automation
Purpose: To automate the generation of compliance documentation for evolving regulatory frameworks using LLM-based content synthesis.
Materials and Reagents:
- Regulatory Knowledge Base: Updated repository of LCA-related regulations (CSRD, ESPR, PEF, DPP) [10]
- Template Library: Standardized reporting templates for different regulatory requirements
- Claim Substantiation Database: Evidence requirements for environmental claims
- Validation Protocols: Methodology for verifying compliance completeness
Procedure:
- Regulatory Monitoring: Continuously update LLM knowledge base with latest regulatory developments and reporting requirements.
- Data Gap Analysis: Systematically identify missing data elements required for specific compliance demonstrations.
- Document Assembly: Generate draft compliance documentation by populating templates with project-specific LCA data.
- Claim Substantiation: Verify all environmental claims against underlying LCA evidence with appropriate uncertainty qualifications.
- Stakeholder Customization: Adapt reporting content and detail level for different audiences (regulators, investors, customers).
- Quality Assurance: Implement automated checks for consistency, completeness, and alignment with regulatory terminology.
Validation Metrics:
- Regulatory requirement coverage (100% of mandatory elements)
- Reduction in manual preparation time (>70%)
- First-pass regulatory acceptance rate (>95%)
Visual Workflows for LLM-Enhanced Chemical LCA
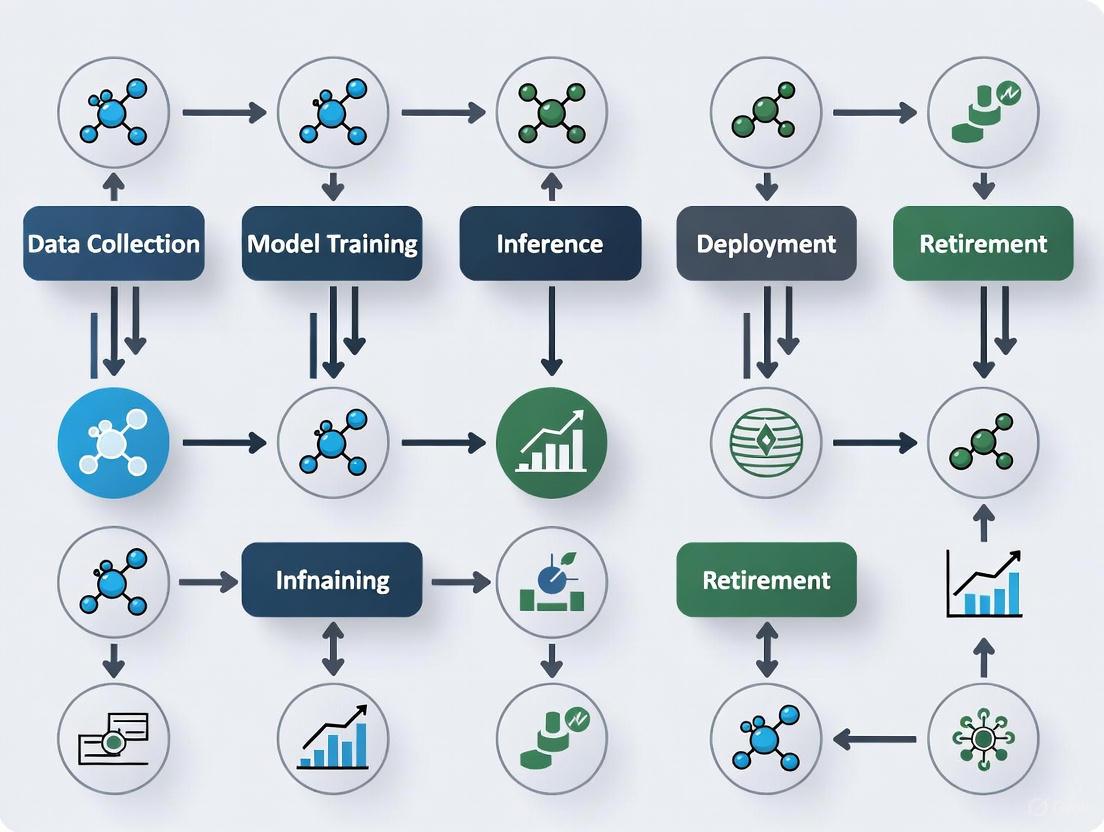
The following diagrams illustrate the integration of LLMs into traditional chemical LCA workflows, highlighting both current applications and emerging opportunities.
Diagram 1: Integration of LLMs within Traditional LCA Workflow. This diagram illustrates how LLM technologies enhance specific phases of the chemical LCA process, particularly in handling data-intensive tasks.
Diagram 2: LLM Architecture for Chemical LCA Data Processing. This diagram outlines the specialized LLM architecture required to transform diverse data inputs into actionable LCA insights, highlighting core processing capabilities.
Table 3: Key Research Reagent Solutions for LLM-Enhanced Chemical LCA
| Tool Category | Specific Solutions | Function in LCA Research |
|---|---|---|
| LLM Platforms & Models | Reasoning-enhanced LLMs (e.g., models with reinforced reasoning training) [11]; Domain-adapted models (e.g., models fine-tuned on chemical literature) | Perform complex pattern recognition across LCA datasets; generate insights from unstructured data; automate reporting tasks |
| LCA Databases & Data Sources | GLAD (Global LCA Data Access) [14]; Ecoinvent database; Proprietary chemical LCA data | Provide foundational life cycle inventory data; enable benchmarking and validation of LLM outputs; ensure data quality |
| Computational Infrastructure | High-performance computing clusters; Cloud-based LLM deployment platforms; Vector databases for embedding storage | Enable processing of large-scale LCA datasets; support fine-tuning of domain-specific models; facilitate rapid experimentation |
| Software & Libraries | Python LCA libraries (Brightway2, Activity-Browser); LLM frameworks (Hugging Face, LangChain); Visualization tools (Graphviz, Plotly) | Support end-to-end LCA modeling; integrate LLM capabilities into existing workflows; create interpretable visualizations |
| Validation & Benchmarking Tools | Standardized LCA datasets with known outcomes; Statistical analysis packages; Uncertainty quantification tools | Verify accuracy of LLM-generated insights; quantify uncertainty in predictions; ensure methodological robustness |
The data-intensive challenges of traditional chemical Life Cycle Assessment represent a significant bottleneck in the chemical industry's sustainability transformation. However, the integration of Large Language Models into LCA workflows offers promising pathways to overcome these limitations through automated data processing, intelligent pattern recognition, and enhanced decision support. By leveraging LLM capabilities for data extraction, analysis, and interpretation, researchers and practitioners can address the core challenges of data complexity, supply chain transparency, and regulatory compliance more effectively than with traditional methods alone.
The experimental protocols and visual workflows presented in this document provide a foundation for implementing LLM-enhanced approaches to chemical LCA. As LLM technologies continue to evolve—particularly in areas of reasoning, domain adaptation, and multimodal processing—their potential to transform chemical life cycle assessment will only increase. Future research should focus on validating these approaches across diverse chemical product categories, improving the integration of uncertainty quantification, and developing standardized benchmarks for evaluating LLM performance in LCA applications. Through continued innovation at the intersection of artificial intelligence and sustainability science, the chemical industry can accelerate its progress toward more sustainable products and processes.
The integration of Large Language Models (LLMs) into chemical research and drug development offers transformative potential for accelerating life cycle assessment (LCA) and molecular discovery. However, this capability comes with a significant and often overlooked environmental cost. The substantial energy and water consumption of training and deploying these models presents a critical paradox: the tools developed to advance science and sustainability are themselves resource-intensive [15] [16]. For researchers and drug development professionals, quantifying this footprint is essential for responsible AI deployment. This document provides detailed application notes and protocols to measure, benchmark, and mitigate the environmental impact of LLMs within a chemical LCA research context.
Quantitative Footprint of LLMs
The environmental footprint of LLMs is primarily measured through energy consumption (and its associated carbon emissions) and water use. The following tables summarize key quantitative data for benchmarking.
Table 1: AI Inference Operational Footprint (Per Prompt)
| Metric | Low-Efficiency Benchmark | High-Efficiency Benchmark (e.g., Gemini) | Equivalent Context |
|---|---|---|---|
| Energy | Up to 29 Wh per long prompt [17] | 0.24 Wh (median text prompt) [18] | Equivalent to watching TV for <9 seconds [18] |
| Carbon Emissions | — | 0.03 gCO2e [18] | — |
| Water Consumption | ~519 mL per 100 words (5 drops per prompt) [19] [18] | 0.26 mL [18] | Five drops of water [18] |
Table 2: Projected Macro-Scale Demand from AI Data Centers
| Resource | Current Consumption (2023-2025) | Projected Consumption (2030) | Context & Drivers |
|---|---|---|---|
| Power Demand | 55 GW (2023) [20] | 84 GW (2027) [20] | 165% increase driven by high-density AI workloads [20]. |
| Electricity Consumption (Global) | 460 TWh (2022) [16] | Approaching 1,050 TWh (2026) [16] | AI is a major driver; could make data centers a top global electricity consumer [16]. |
| Direct Water Use (U.S.) | 66 billion liters (2023) [21] | Increasing in parallel with energy [19] | Driven by cooling needs; varies significantly by local climate and cooling technology [19] [21]. |
Experimental Protocols for Footprint Measurement
Accurately measuring the resource consumption of LLMs requires a comprehensive methodology that moves beyond theoretical chip-level calculations to account for real-world, full-system overhead.
Protocol: Comprehensive Life Cycle Inventory for LLM Inference
This protocol outlines a framework for quantifying the energy, carbon, and water footprint of an LLM inference task, such as an API call to a commercial model.
1. Goal and Scope Definition:
- Functional Unit: Define the system's function. For LLM inference, this is typically a single query or prompt, characterized by input and output token length [17].
- System Boundary: The assessment must include:
- Dynamic Power of Full System: Energy used by the primary ML accelerators (TPUs/GPUs), host CPUs, and RAM during active computation [18].
- Idle Power Attribution: Energy consumed by provisioned but idle capacity, required for reliability and traffic spikes [18].
- Data Center Overhead: Energy for cooling, power distribution, and other support infrastructure, measured by Power Usage Effectiveness (PUE) [18].
- Water Consumption: Water evaporated for on-site cooling and water consumed in the generation of the electricity used [19] [21].
2. Life Cycle Inventory (LCI) Data Collection:
- Energy Measurement: Combine direct power measurements with infrastructure multipliers.
- Method A (API-based): For commercial models, use a benchmarking framework that pairs API performance data (e.g., latency, tokens per second) with provider-specific environmental multipliers for energy and carbon [17].
- Method B (Infrastructure-aware): For open-source models, measure power draw at the GPU/TPU level using profiling tools (e.g.,
nvmlfor NVIDIA GPUs). To account for full-system consumption, a common heuristic is to double the GPU power draw to include CPUs, fans, and other overheads [15]. - Apply PUE: Multiply the total IT equipment energy by the data center's PUE to account for infrastructure overhead. Google's fleet-wide average PUE is 1.09, but this varies by facility [18].
- Calculate Carbon: Multiply total energy (kWh) by the local grid's carbon intensity (gCO2e/kWh) [18].
- Water Measurement: Calculate water footprint using direct and indirect factors.
- Direct Water: Multiply the total energy consumed (kWh) by the data center's Water Usage Effectiveness (WUE), reported in liters/kWh. The average WUE across data centers is 1.9 L/kWh [19].
- Indirect Water from Electricity: Multiply energy from the grid (kWh) by the water intensity of the power source (e.g., ~1.2 gallons/kWh U.S. average in 2023) [19].
3. Interpretation:
- Report results per functional unit (e.g., energy/query, water/query).
- Conduct sensitivity analysis on key parameters (e.g., prompt length, model size, grid location) [15].
- Compare results against benchmarks (see Table 1) to contextualize performance.
Protocol: LLM-Assisted Data Retrieval for Chemical LCA
This protocol leverages a domain-specific LLM to automate life cycle inventory (LCI) data retrieval from scientific literature, significantly reducing the manual research time and associated environmental burden [22].
1. Model Selection and Retraining:
- Base Model: Select a suitable open-weight model (e.g.,
LLaMA-2-7B) [22]. - Domain Adaptation (Pre-training): Inject domain knowledge by continuing pre-training on a curated corpus of scientific texts related to the LCA domain (e.g., methanol production, plastic packaging EoL treatment) [22].
- Task Fine-tuning: Fine-tune the model for specific downstream tasks:
2. Workflow Execution:
- Stage 1 - Document Identification: The fine-tuned classification model screens a corpus of literature (e.g., PDFs from PubMed, ACS Publications) to identify relevant studies [22].
- Stage 2 - Information Retrieval: A RAG pipeline is used to fetch the most relevant text chunks from the pre-identified documents based on a user query (e.g., "What is the global warming potential for producing 1 kg of methanol from biomass?").
- Stage 3 - Data Extraction: The fine-tuned Q&A model processes the retrieved context to generate a precise answer containing the requested LCI data [22].
3. Validation:
- Validate the framework's performance by comparing its extracted data against ground-truth sources like the USLCI database or manual expert extraction [22].
- Target performance metrics include high accuracy in document classification (>0.85) and high F1 scores for Q&A (>0.82) [22].
The following workflow diagram illustrates the protocol for comprehensive footprint measurement and the LLM-assisted data retrieval for chemical LCA.
The Scientist's Toolkit: Research Reagents & Materials
This section details key "research reagents"—technologies and strategies—essential for developing and deploying more sustainable LLMs in a research environment.
Table 3: Key Reagents for Sustainable AI Research
| Reagent Solution | Function & Mechanism | Application in LCA Research |
|---|---|---|
| Mixture-of-Experts (MoE) Models | Activates only a small subset of the model's neural network for a given query, reducing computations and data transfer by 10-100x [18]. | Running large, multi-purpose models for various LCA tasks (e.g., data extraction, impact interpretation) with lower operational footprint. |
| Quantization (e.g., AQT) | Reduces the numerical precision of model weights (e.g., from 32-bit to 8-bit), decreasing memory use and energy consumption without significant quality loss [18]. | Deploying models on local infrastructure or with smaller hardware footprints for faster, less energy-intensive inference. |
| Advanced Cooling Systems | Dissipates heat more efficiently than air cooling. Immersion cooling, where hardware is submerged in dielectric fluid, offers significant energy and water savings [19] [21]. | Essential for siting high-performance computing (HPC) clusters for AI model training in water-stressed regions. Reduces direct operational water footprint. |
| Carbon-Aware Computing | Schedules and routes non-urgent AI training jobs to times and locations where grid carbon intensity is lowest (e.g., when solar/wind are abundant) [23]. | A strategy for researchers to minimize the carbon footprint of long-running model training or large batch inference jobs for LCA. |
| Retrieval Augmented Generation (RAG) | Grounds an LLM on a specific, external knowledge base (e.g., a proprietary LCI database) to reduce "hallucinations" and improve accuracy without retraining the entire model [22]. | Creating highly accurate, domain-specific LCA assistants that provide reliable data, reducing time and resource waste from error correction. |
The environmental footprint of LLMs is a non-trivial factor that must be integrated into the planning and execution of chemical life cycle assessment research. By adopting the standardized measurement protocols, benchmarking against quantitative data, and leveraging the "reagents" of efficient models and computing strategies outlined in this document, researchers and drug development professionals can harness the power of AI responsibly. This ensures that the pursuit of scientific innovation and sustainability through AI does not come at an unacceptable cost to the planet.
The integration of Large Language Models (LLMs) into chemical life cycle assessment and drug development represents a fundamental transformation in research methodology rather than a replacement of human expertise. This paradigm shift positions AI as a collaborative partner that accelerates discovery while leveraging human scientific intuition. Chemical research has traditionally faced significant challenges, including efficiency bottlenecks where drug discovery requires screening 10⁴-10⁶ compounds over 5-10 years, data management difficulties with millions of dispersed chemical data points in heterogeneous formats, and complex system modeling challenges for problems like protein folding that demand enormous computational resources [24]. Within this context, LLMs have evolved from simple pattern recognition tools to sophisticated partners capable of augmenting human intelligence across the entire chemical research lifecycle.
The progression of AI in chemistry has moved through three distinct phases: the 1.0 stage (1980s-2010s) characterized by rules and statistical models like QSAR with limited generalization capability; the 2.0 stage (2010s-2020s) marked by deep learning approaches using CNNs for spectra and GNNs for molecular graphs that improved prediction accuracy but still required human experimental guidance; and the current 3.0 stage (2020s-present) defined by intelligent agent systems that create closed-loop cycles of "data input→model reasoning→experimental decision→result feedback→model update" [24]. This evolution has transformed LLMs from passive tools into active collaborators that enhance rather than replace scientific expertise, particularly in complex domains like chemical life cycle assessment where contextual understanding and multi-stage evaluation are critical.
Table: Evolution of AI in Chemical Research
| Phase | Time Period | Key Technologies | Capability Level | Human Role |
|---|---|---|---|---|
| AI 1.0 | 1980s-2010s | QSAR, Molecular Fingerprints, Statistical Models | Limited Generalization | Full experimental control |
| AI 2.0 | 2010s-2020s | Deep Learning (CNN, RNN, GNN), Pattern Recognition | Improved Prediction Accuracy | Experimental design & guidance |
| AI 3.0 | 2020s-Present | LLM Agents, Autonomous Experimentation, Closed-Loop Systems | Autonomous Research Capability | Strategic oversight & expertise integration |
Application Notes: LLM-Driven Acceleration in Chemical Research
Molecular Design and Optimization
LLMs function as force multipliers in molecular design by rapidly exploring chemical space and predicting structure-property relationships that would require extensive experimental investigation through traditional methods. Specialized scientific language models like ChemBERTa and MolBERT represent molecular structures as embeddings in continuous vector spaces, capturing complex chemical similarities and relationships that enable property prediction and analog generation [24] [25]. These models learn the fundamental mapping between molecular structure and chemical properties (SPF relationships), allowing researchers to focus experimental efforts on the most promising candidates. For example, Chemformer models have demonstrated exceptional capability in reaction prediction and optimization tasks, achieving accuracy levels that surpass human chemists in specific domains [25].
The integration of multi-modal approaches represents a particular strength of LLM-enabled molecular design. By combining molecular graph data with spectral information, textual research findings, and experimental results, these systems develop a comprehensive understanding of chemical behavior that transcends single-data-type approaches. Vision Transformer architectures processing infrared spectra coupled with GNNs analyzing molecular structure have shown significantly improved prediction accuracy for complex chemical properties compared to single-modality approaches [24]. This multi-modal capability is especially valuable in chemical life cycle assessment, where environmental impact, synthetic complexity, and functional performance must be balanced simultaneously.
Reaction Prediction and Optimization
The application of LLMs to reaction prediction and optimization has demonstrated remarkable acceleration in synthetic planning, with systems like IBM's RXN for Chemistry achieving unprecedented accuracy in predicting reaction outcomes and suggesting optimal conditions [24]. These models leverage vast chemical corpora including patents, research articles, and experimental data to identify patterns and relationships that inform synthetic planning. The core capability lies in the models' capacity to process chemical representations—particularly SMILES strings and molecular graphs—to predict reactivity, selectivity, and potential side products with accuracy rates exceeding traditional computational methods while requiring minimal computational resources [26].
Beyond forward prediction, LLMs excel at retrosynthetic analysis, decomposing target molecules into feasible synthetic pathways using available starting materials. Systems leveraging transformer architectures trained on reaction databases can propose multiple synthetic routes with assessment of step efficiency, atom economy, and potential hazards [25]. When integrated with robotic experimentation platforms, these systems create closed-loop environments where predictions inform experiments, results refine models, and the cycle continues autonomously. For instance, the RoboChem platform demonstrated the capability to complete approximately 20 molecular syntheses and optimizations per week—equivalent to a traditional research team's six-month output—through this continuous integration of prediction and experimentation [26].
Table: Quantitative Performance of LLMs in Chemical Research Applications
| Application Area | Traditional Method Timeline | LLM-Accelerated Timeline | Performance Improvement | Key Enabling Technologies |
|---|---|---|---|---|
| Molecular Design | 12-18 months | 2-5 months | 90% reduction in lead identification time [26] | GNNs, Transformer Models, Molecular Embeddings |
| Reaction Optimization | 3-6 months | 2-4 weeks | 40% improvement in parameter optimization efficiency [26] | Retrosynthesis Algorithms, Condition Prediction Models |
| ADMET Prediction | 4-8 weeks | 1-2 days | Accuracy exceeding traditional QSAR methods [25] | Multi-task Learning, Transfer Learning |
| Experimental Execution | Manual processes (days) | Automated workflows (hours) | 30x increase in experimental throughput [26] | Robotic Platforms, Autonomous Lab Equipment |
Chemical Life Cycle Assessment
LLMs bring transformative capabilities to chemical life cycle assessment by integrating diverse data sources—from synthetic pathways and environmental impact databases to regulatory frameworks and economic factors—into a comprehensive analytical framework. Specialized models can process technical literature, patent databases, and chemical inventories to map the complete life cycle of chemical products, from raw material extraction through production, use, and disposal [27]. This systems-level analysis enables researchers to identify environmental hotspots, evaluate green chemistry alternatives, and predict unintended consequences before committing to extensive laboratory work or production scaling.
The capacity of LLMs to navigate complex, multi-dimensional constraints makes them particularly valuable for sustainable chemical design. Models can simultaneously optimize for functionality, synthetic efficiency, and environmental impact by accessing and processing specialized databases like Ecoinvent, GaBi, and US LCI that contain detailed environmental impact factors for thousands of chemical processes and materials [27]. For example, an LLM system might identify a catalytic alternative that reduces energy consumption by 40% while maintaining yield, or suggest a biodegradable structural analog that eliminates persistent environmental pollutants—decisions that would be extraordinarily time-consuming through manual literature review alone.
Experimental Protocols: Methodologies for LLM Integration
Protocol 1: LLM-Augmented Molecular Property Prediction
Objective: To predict key molecular properties (solubility, toxicity, biological activity) using LLM embeddings and validate predictions through experimental testing.
Materials and Reagents:
- Chemical compounds for validation (purity >95%)
- Molecular representation software (RDKit, OpenBabel)
- Pre-trained scientific LLM (ChemBERTa, MolBERT)
- Assay materials for experimental validation
- Statistical analysis software (Python, R)
Procedure:
- Molecular Representation: Convert chemical structures to standardized SMILES notation and compute molecular descriptors using RDKit. Generate alternative representations (molecular graphs, fingerprints) for multi-modal analysis.
- LLM Embedding Generation: Process molecular representations through pre-trained scientific LLMs to generate embedding vectors that capture structural and functional characteristics. For transformer models, use attention mechanisms to identify structurally significant molecular substructures.
- Property Prediction: Feed molecular embeddings into prediction heads (fully connected neural networks) trained on curated chemical datasets (ChEMBL, PubChem) to estimate target properties. Implement ensemble methods where multiple models contribute to final predictions with confidence intervals.
- Experimental Validation: Select compounds representing prediction confidence extremes (high-confidence vs. borderline predictions) for experimental testing. Perform standardized assays (e.g., solubility measurement, cytotoxicity testing) under controlled conditions.
- Model Refinement: Incorporate experimental results into training data for model fine-tuning. Implement active learning strategies to prioritize compounds for testing that maximize model improvement.
Validation Metrics:
- Prediction accuracy (R², RMSE) against held-out test sets
- Early recognition performance (enrichment factors at 1%, 5% of screened library)
- Computational efficiency (screening rate in molecules/second)
- Experimental confirmation rate (% of predictions validated)
Protocol 2: Retrosynthetic Planning with LLM Guidance
Objective: To develop optimized synthetic routes for target molecules using LLM-based retrosynthetic analysis and validate routes through experimental execution.
Materials and Reagents:
- Target molecule specification (structure, purity requirements)
- Available starting material inventory
- Chemical reaction databases (Reaxys, SciFinder)
- Retrosynthetic planning software (ASKCOS, IBM RXN)
- Laboratory equipment for synthetic validation
Procedure:
- Route Generation: Input target molecule SMILES into LLM-powered retrosynthetic analysis system. Generate multiple synthetic routes using template-based and template-free approaches with step-by-step rationales.
- Route Evaluation: Assess generated routes using multi-criteria scoring including step count, atom economy, predicted yield, safety considerations, and starting material availability. Apply constraint optimization to prioritize routes aligning with sustainability principles.
- Condition Optimization: For selected routes, predict optimal reaction conditions (catalyst, solvent, temperature, concentration) using reaction outcome prediction models. Identify potential side products and purification challenges.
- Experimental Validation: Execute top-ranked synthetic routes in laboratory setting. Monitor reaction progress (TLC, LC-MS) and isolate products for characterization (NMR, HRMS).
- Knowledge Integration: Document experimental results and refinements to original predictions. Update model parameters to incorporate new synthetic knowledge, creating a self-improving system.
Validation Metrics:
- Route feasibility (successful execution rate)
- Synthetic efficiency (yield, purity, step count reduction)
- Material efficiency (atom economy, E-factor)
- Prediction accuracy (condition success rate)
Protocol 3: Chemical Life Cycle Assessment Using LLM Integration
Objective: To conduct comprehensive life cycle assessments of chemical products using LLM-powered data integration and analysis.
Materials and Reagents:
- LCA software (OpenLCA, SimaPro)
- LCA databases (Ecoinvent, GaBi, US LCI)
- Chemical process data (energy inputs, waste streams, emissions)
- LLM with access to scientific literature and regulatory databases
Procedure:
- Goal and Scope Definition: Define assessment boundaries, functional units, and impact categories. Use LLMs to identify relevant regulatory frameworks and industry standards for compliance.
- Inventory Analysis: Compile energy and material inputs, emissions, and waste streams across the chemical's life cycle. Deploy LLMs to extract and standardize data from disparate sources (technical reports, patents, supplier information).
- Impact Assessment: Calculate environmental impacts using standardized methods (ReCiPe, TRACI). Apply LLMs to identify impact hotspots and contribution analysis through natural language interpretation of results.
- Interpretation and Improvement: Generate improvement recommendations using LLM analysis of alternative materials, processes, and technologies. Create scenario comparisons with projected environmental benefits.
- Reporting and Documentation: Automate generation of assessment reports, executive summaries, and regulatory compliance documentation using LLM writing capabilities.
Validation Metrics:
- Database coverage and relevance
- Uncertainty quantification in assessments
- Improvement potential identification rate
- Regulatory compliance alignment
The Scientist's Toolkit: Essential Research Reagents and Solutions
The effective implementation of LLM-accelerated chemical research requires both computational and experimental components working in concert. The following toolkit represents essential resources across both domains:
Table: Essential Research Reagents and Computational Tools for LLM-Accelerated Chemistry
| Tool Category | Specific Examples | Function | Access Method |
|---|---|---|---|
| Scientific LLMs | ChemBERTa, MolBERT, Geneformer | Domain-specific language understanding for chemical and biological data | API access, Open-source implementations |
| Chemical Databases | ChEMBL, PubChem, CAS | Curated chemical structures, properties, and bioactivity data | Public APIs, Licensed access |
| LCA Databases | Ecoinvent, GaBi, US LCI | Environmental impact factors for chemical processes | Licensed database access |
| Molecular Representation | RDKit, OpenBabel, SMILES | Standardized chemical structure representation and manipulation | Open-source libraries |
| Reaction Prediction | IBM RXN, ASKCOS | Retrosynthetic analysis and reaction condition prediction | Web interfaces, APIs |
| Automation Platforms | RoboChem, CLARify | Automated execution of chemical synthesis and testing | Integrated hardware-software systems |
| Multi-modal AI | Vision Transformer, GNNs | Processing diverse data types (spectra, structures, text) | Deep learning frameworks |
| Collaboration Frameworks | AutoGen, LangChain | Multi-agent systems for complex problem decomposition | Open-source frameworks |
Implementation Framework: From Theory to Practice
Human-AI Collaborative Workflows
The successful integration of LLMs into chemical research requires thoughtfully designed collaborative workflows that leverage the respective strengths of human and artificial intelligence. Effective frameworks position LLMs as research assistants that handle data-intensive tasks while humans provide strategic direction and nuanced interpretation. For example, in drug discovery, LLMs can rapidly identify potential lead compounds by scanning chemical space and predicting properties, while medicinal chemists apply their understanding of synthetic feasibility, patent landscape, and clinical requirements to make final selections [25] [28]. This division of labor has demonstrated remarkable efficiency improvements, with systems like Insilico Medicine's Chemistry42 reducing the timeline for clinical candidate identification from traditional 4-6 years to approximately 18 months while cutting costs to one-third of conventional approaches [24].
The human-AI interface is particularly critical for handling unexpected results and edge cases where training data may be limited. Researchers should establish protocols for LLM output validation, with clearly defined confidence thresholds that trigger human review. For instance, molecular predictions with confidence scores below 0.85 might automatically route to expert evaluation before experimental commitment. Similarly, contradictory predictions from multiple models (e.g., conflicting toxicity assessments) should flag for human arbitration. These guardrails ensure that the acceleration benefits of LLMs don't come at the cost of scientific rigor, particularly in regulated environments like pharmaceutical development where erroneous conclusions have significant consequences.
Evaluation and Validation Frameworks
Robust evaluation methodologies are essential for assessing the performance and reliability of LLM systems in chemical research contexts. Beyond traditional accuracy metrics, evaluation should encompass scientific utility, innovation potential, and practical efficiency gains. Frameworks like GraphArena provide structured assessment approaches, categorizing outputs as Correct (scientifically valid and optimal), Suboptimal (scientifically valid but non-optimal), or Hallucinatory (scientifically invalid) [29]. This granular evaluation is particularly important for chemical applications where partially correct solutions might still have practical value, but scientifically invalid suggestions must be identified and filtered.
Validation should occur across multiple dimensions including computational performance, experimental verification, and expert assessment of scientific plausibility. The AR-Bench framework offers methodologies for evaluating active reasoning capabilities—testing how well models can construct reasoning chains, propose hypotheses, gather evidence, and validate conclusions rather than simply retrieving memorized information [29]. This is especially relevant for chemical life cycle assessment, where complex trade-offs and multi-variable optimization require genuine reasoning rather than pattern matching. Implementing these comprehensive evaluation frameworks ensures that LLM acceleration delivers both speed and reliability, maintaining scientific standards while dramatically reducing development timelines.
The positioning of LLMs as accelerators rather than replacements in chemical research represents both a practical approach and a philosophical commitment to human expertise at the center of scientific discovery. The documented applications and protocols demonstrate that the most significant gains occur when LLMs handle data-intensive, repetitive, and pattern-recognition tasks while humans focus on strategic planning, creative problem-solving, and complex decision-making. This collaborative model has already demonstrated transformative potential across chemical life cycle assessment, molecular design, and drug development, with documented reductions in development timelines from years to months and substantial cost savings while maintaining scientific rigor.
Looking forward, the continued evolution of LLM capabilities—particularly in reasoning, multi-modal integration, and specialized scientific knowledge—promises even greater acceleration potential. However, the fundamental principle remains unchanged: these systems serve as amplifiers of human intelligence rather than autonomous scientists. The most successful research organizations will be those that strategically implement the protocols and frameworks outlined here, creating structured collaborations that leverage the unique strengths of both human and artificial intelligence. Through this approach, the chemical research community can address increasingly complex challenges—from sustainable chemistry to personalized therapeutics—with unprecedented speed and efficiency while maintaining the scientific integrity that remains the foundation of meaningful discovery.
The integration of Large Language Models (LLMs) and other artificial intelligence (AI) technologies into environmental science is creating a transformative paradigm for addressing complex sustainability challenges. This convergence is particularly impactful in the specialized domain of chemical life cycle assessment (LCA), where it enables researchers to quantify environmental impacts from raw material extraction to end-of-life treatment with unprecedented speed and precision [30] [31]. The application of these computational approaches is revolutionizing sustainable drug development by allowing researchers to rapidly predict and optimize the environmental footprints of pharmaceutical compounds and processes [32] [30]. However, effective collaboration across these disciplines requires a shared understanding of key terminologies, methodologies, and frameworks that bridge the computational and environmental domains. This document provides essential application notes and experimental protocols to equip researchers, scientists, and drug development professionals with the tools needed to leverage LLMs effectively within chemical LCA research, thereby facilitating more sustainable therapeutic development.
Key Terminologies: A Cross-Disciplinary Lexicon
Table 1: Foundational Terminologies Bridging AI and Environmental Science
| Terminology | Domain | Definition | Relevance to Chemical LCA |
|---|---|---|---|
| Large Language Model (LLM) | Artificial Intelligence | A deep learning model trained on vast amounts of text data to understand, generate, and manipulate human language [33]. | Processes scientific literature to extract life cycle inventory (LCI) data and environmental impact information [22]. |
| Life Cycle Assessment (LCA) | Environmental Science | A standardized methodology (ISO 14040/14044) for evaluating the environmental impacts associated with all stages of a product's life cycle [31]. | Provides the foundational framework for quantifying environmental impacts of chemicals and pharmaceuticals [30]. |
| Life Cycle Inventory (LCI) | Environmental Science | The phase of LCA involving the compilation and quantification of inputs and outputs for a product system throughout its life cycle [31]. | Serves as the primary data source for environmental impact calculations; often targeted for AI-assisted retrieval [22]. |
| Retrieval Augmented Generation (RAG) | Artificial Intelligence | A technique that enhances LLMs by retrieving relevant information from external knowledge bases before generating responses [22]. | Improves accuracy of LCI data extraction from scientific literature and databases [22]. |
| Zero-Shot Anomaly Detection | Artificial Intelligence | The capability of a model to identify anomalies or outliers in data without having been specifically trained on similar examples [33]. | Detects irregularities in environmental monitoring data from sustainable systems without task-specific training [33]. |
| Model Drift | Artificial Intelligence | The degradation of model performance over time due to changes in data distribution or relationships between variables [34] [31]. | Critical for maintaining accuracy in predictive LCA models as chemical processes and environmental data evolve [31]. |
| Prompt Injection | AI Security | A type of attack where maliciously crafted prompts manipulate LLM behavior to produce unintended outputs [34]. | A security concern when using LLMs for environmental data analysis in regulated contexts like pharmaceutical LCA [34]. |
| Carbon Footprint | Environmental Science | The total amount of greenhouse gases emitted directly or indirectly by an activity, product, or organization [30]. | A key impact category measured in chemical LCA, often predicted using machine learning models [30]. |
| LLM Observability | AI Operations | The practice of monitoring LLM applications in production to track performance, usage metrics, and output quality [34]. | Ensures reliability and compliance of AI systems used for automated LCA in pharmaceutical development [34]. |
Quantitative Performance Data in AI-Enhanced Chemical LCA
Table 2: Performance Metrics of AI/LLM Approaches in Chemical LCA Research
| AI Methodology | Application Context | Performance Metrics | Comparative Baseline | Reference |
|---|---|---|---|---|
| Sustain-LLaMA Framework (Fine-tuned LLaMA-2-7B) | LCI data extraction from scientific literature | Classification accuracy: 0.850-0.952; F1 score: 0.823-0.855 | Outperformed non-retrained LLaMA-2-7B and showed comparable/superior accuracy to ChatGPT-4o [22] | Kumar et al., 2025 [22] |
| SigLLM Framework (GPT-3.5 Turbo, Mistral) | Anomaly detection in sustainable infrastructure monitoring | Effectively detected anomalies across 11 datasets (492 univariate time series, 2,349 anomalies); performed better than some deep learning transformers but ~30% less accurate than state-of-the-art specialized models (e.g., AER) [33] | Veeramachanani et al., 2024 [33] | |
| Molecular-Structure-Based ML | Prediction of chemicals' life-cycle environmental impacts | Most promising technology for rapid prediction; accuracy depends on training data quality and feature engineering [30] | Addresses limitations of conventional LCA: slow speed and high cost [30] | Green Carbon, 2025 [30] |
| AI-Enhanced Drug Discovery | Target identification and compound screening | Increased compound success rate from 10% (traditional) to 15-20%; reduced single-drug R&D costs by 30-50% [35] | Traditional drug development: 12-15 years, $2.6B average [35] | Zhong Lun, 2025 [35] |
Experimental Protocols for AI-Driven Chemical LCA
Protocol 1: LLM-Based Life Cycle Inventory Data Extraction
Objective: To implement a systematic framework for extracting Life Cycle Inventory (LCI) and environmental impact data from scientific literature using a fine-tuned LLM.
Materials and Reagents:
- Scientific literature corpus (PDF formats)
- High-performance computing resources (GPU clusters recommended)
- LLaMA-2-7B base model or similar open-source LLM
- Domain-specific environmental science texts for retraining
- Annotation tools for data labeling
Methodology:
- Document Relevance Classification:
- Fine-tune a classification model (e.g., BERT-based classifier) on a labeled dataset of relevant and non-relevant scientific documents for your chemical domain (e.g., methanol production, plastic packaging).
- Apply the trained classifier to filter a large corpus of scientific literature, retaining only documents pertinent to the target LCI data.
- Validate classification accuracy (>0.85) on a held-out test set before proceeding [22].
Domain Adaptation Pre-training:
- Pre-train the selected LLM (e.g., LLaMA-2-7B) on the relevant scientific texts identified in Step 1.
- This injects domain-specific knowledge (e.g., LCA terminology, chemical processes) into the model's parameters.
- Use a language modeling objective with a context window sufficient for scientific paragraphs.
Question-Answering Model Fine-tuning with RAG:
- Fine-tune the domain-adapted LLM as a question-answering model specifically for LCI data extraction.
- Implement a Retrieval Augmented Generation (RAG) system where the model retrieves relevant text passages from the scientific literature before generating answers to LCI-related queries.
- Train the model on a curated dataset of LCI questions and their corresponding answers extracted from annotated texts.
- Target performance: F1 scores of 0.82-0.85 on held-out test questions [22].
Validation and Benchmarking:
- Validate the framework's extracted LCI data against established databases (e.g., USLCI) and manual expert extractions.
- Compare performance against general-purpose LLMs (e.g., ChatGPT-4o) to quantify improvement gains.
Workflow for LCI Data Extraction
Protocol 2: Molecular-Structure-Based Prediction of Chemical Life-Cycle Impacts
Objective: To develop machine learning models for rapid prediction of life-cycle environmental impacts of chemicals directly from molecular structures, bypassing traditional LCA data requirements.
Materials and Reagents:
- Chemical databases with molecular structures (SMILES, InChI)
- LCA database with environmental impact factors
- Python environment with RDKit, Scikit-learn, PyTorch/TensorFlow
- High-performance computing resources for model training
Methodology:
- Dataset Curation:
- Compile a comprehensive dataset pairing chemical structures with their life-cycle environmental impacts (e.g., carbon footprints, toxicity potentials).
- Address data scarcity by integrating multiple sources and applying data augmentation techniques where appropriate.
- Ensure data quality through rigorous validation against experimental measurements.
Molecular Feature Engineering:
- Compute molecular descriptors (e.g., molecular weight, octanol-water partition coefficient, topological surface area) from chemical structures.
- Alternatively, employ graph-based representations that directly encode molecular structure as graphs for use with graph neural networks.
- Identify features most predictive of LCA results through feature importance analysis.
Model Selection and Training:
- Implement and compare multiple machine learning algorithms, including random forests, gradient boosting machines, and graph neural networks.
- Train models to predict environmental impact categories (global warming potential, aquatic toxicity, etc.) from molecular features.
- Utilize cross-validation to optimize hyperparameters and prevent overfitting.
Model Validation and Interpretation:
- Validate model predictions against hold-out test sets of chemicals with known life-cycle impacts.
- Employ model interpretation techniques (e.g., SHAP values) to identify which molecular features drive specific environmental impacts.
- Integrate with LLMs for enhanced feature engineering and database building, as LLMs are expected to provide new impetus for these tasks [30].
ML Model for Chemical Impact Prediction
Protocol 3: LLM Observability for Compliant Environmental Assessment
Objective: To implement LLM observability protocols that ensure reliability, compliance, and performance monitoring of LLM systems used in chemical LCA research, particularly for drug development applications.
Materials and Reagents:
- LLM observability platform (commercial or open-source)
- SDKs/APIs for application instrumentation
- Dashboard visualization tools
- Compliance checklists for pharmaceutical regulations
Methodology:
- System Instrumentation:
- Integrate Software Development Kits (SDKs) or APIs into LLM applications to capture key telemetry data.
- Implement OpenTelemetry (OTel) integration for consistent generation of traces, metrics, and logs across distributed systems.
- Capture inputs, outputs, latency, token usage, and errors for all LLM interactions.
Performance and Quality Monitoring:
- Track key performance metrics: latency, throughput, token usage, and error rates.
- Implement quality assessment metrics specific to LCA applications: hallucination rates (factual inaccuracies in LCI data), relevance of retrieved information, and toxicity of outputs.
- Set up automated alerts for performance degradation or quality threshold violations.
Safety and Compliance Checks:
- Monitor for prompt injection attacks that might manipulate environmental assessment results.
- Detect potential leakage of sensitive data (e.g., proprietary chemical formulations).
- Track compliance signals relevant to pharmaceutical regulations and environmental reporting standards.
Visualization and Continuous Improvement:
- Create customized dashboards visualizing key metrics for different stakeholder groups.
- Implement A/B testing capabilities to compare different prompts, models, or retrieval strategies.
- Establish feedback loops for model retraining and refinement based on observed performance and emerging data patterns.
LLM Observability Framework
Table 3: Key Research Reagents and Computational Solutions for AI-Enhanced Chemical LCA
| Item/Resource | Category | Function/Application | Implementation Example |
|---|---|---|---|
| Sustain-LLaMA | Specialized LLM | Domain-adapted language model for extracting LCI and environmental impact data from scientific literature [22]. | Fine-tuned on methanol production and plastic packaging literature; achieves high accuracy in LCI data retrieval [22]. |
| React-OT Model | Chemistry AI Model | Accelerates transition state prediction in chemical reactions to sub-second speeds with high accuracy [32]. | Used in molecular simulation for drug discovery; improves understanding of reaction pathways and energy requirements [32]. |
| GPU Clusters (NVIDIA H100, A100) | Computational Hardware | Provides accelerated computing for training and running large AI models, including LLMs and molecular graph neural networks [36]. | Training of BloombergGPT used 512 A100 GPUs; essential for handling computational demands of AI-enhanced LCA [36]. |
| OpenTelemetry (OTel) | Observability Framework | Open-source framework for generating and collecting telemetry data (metrics, logs, traces) from LLM applications [34]. | Instruments LLM systems for chemical LCA to monitor performance, costs, and compliance requirements [34]. |
| PandaOmics Platform | Drug Discovery AI | AI platform for target identification using deep feature synthesis, causal inference, and pathway reconstruction on multi-omics data [35]. | Identified TNIK as promising anti-fibrotic target; enables more sustainable drug development through accurate early target prioritization [35]. |
| Retrieval Augmented Generation (RAG) | AI Architecture | Enhances LLM accuracy by retrieving relevant information from external knowledge bases before generating responses [22]. | Implemented in Sustain-LLaMA to improve precision of LCI data extraction from scientific literature [22]. |
| AI Credibility Assessment Framework | Regulatory Compliance | Risk-based framework for establishing credibility of AI models used in pharmaceutical development and regulatory submissions [37]. | FDA-proposed approach for evaluating AI models that generate data supporting drug safety, efficacy, or quality assessments [37]. |
The integration of LLMs and AI technologies into chemical life cycle assessment represents a frontier in sustainable pharmaceutical research and development. The protocols and frameworks presented herein provide actionable methodologies for leveraging these advanced computational tools to accelerate environmental impact assessment while maintaining scientific rigor and regulatory compliance. As these fields continue to converge, researchers equipped with both the terminological foundation and practical implementation guidelines outlined in this document will be uniquely positioned to drive innovations in sustainable drug development. The critical importance of maintaining human expertise in the loop while adopting these automated approaches cannot be overstated—the most successful implementations will harmonize computational power with scientific domain knowledge to create truly transformative environmental assessment capabilities.
From Theory to Therapy: Applying LLMs in Drug Discovery and LCA Workflows
Within chemical life cycle assessment (LCA) and drug development research, the systematic review (SR) represents a cornerstone of evidence-based practice, yet its execution is notoriously slow and resource-intensive. The growing demand for high-quality SRs, coupled with the rapid emergence of new biomedical literature, creates a significant bottleneck in research and development pipelines. This application note details how Large Language Models (LLMs) are being leveraged to automate critical stages of the systematic review process, thereby accelerating biological summarization and therapeutic target evaluation. By framing this automation within the context of a broader thesis on LLMs in chemical LCA research, we provide researchers and drug development professionals with validated protocols and tools to enhance the efficiency, reproducibility, and scope of their evidence-synthesis activities.
Systematic reviews in biomedicine are methodologically rigorous and involve multiple sequential stages, from literature search to final reporting. Automation technologies, particularly LLMs, have been proposed to expedite this workflow, reduce manual workload, and minimize human error [38]. A comprehensive overview of SR automation studies indexed in PubMed indicates that automation techniques are being developed for all SR stages, though real-world adoption remains limited [38].
The distribution of automation efforts across the systematic review workflow is summarized in Table 1.
Table 1: Distribution of Automation Applications Across Systematic Review Stages
| Systematic Review Stage | Proportion of Automated Studies (%) | Primary Automation Goals |
|---|---|---|
| Search | 15.4% | Identifying relevant publications from databases [38]. |
| Record Screening | 72.4% | Prioritizing and selecting studies based on title/abstract [38]. |
| Full-Text Selection | 4.9% | Applying inclusion/exclusion criteria to full articles [38]. |
| Data Extraction | 10.6% | Extracting structured data (e.g., chemicals, impacts) from text [38] [22]. |
| Risk of Bias Assessment | 7.3% | Evaluating the methodological quality of included studies [38]. |
| Evidence Synthesis | 1.6% | Summarizing findings and generating conclusions [38]. |
| Reporting | 1.6% | Assisting in the drafting of the review manuscript [38]. |
The performance of these automated tools can vary significantly across different review topics. For instance, automated record screening, the most commonly targeted stage, shows large variations in sensitivity and specificity depending on the SR's subject matter [38]. This highlights the need for rigorous validation within a specific research domain, such as chemical LCA or drug target evaluation.
Application Note: Sustaining-LLM for Data Retrieval in Chemical LCA
A prime example of a domain-specific LLM application is the "Sustain-LLaMA" framework, designed to retrieve Life Cycle Inventory (LCI) and environmental impact data from scientific literature [22]. This framework addresses a critical challenge in chemical LCA: the time-consuming and costly process of obtaining reliable, transparent LCI data.
Experimental Protocol for LCI Data Retrieval
The following protocol, adapted from Kumar et al. (2025), provides a step-by-step methodology for implementing an LLM-based data retrieval system [22].
- Objective: To automatically extract LCI and environmental impact data for a given chemical or process (e.g., methanol production, plastic packaging end-of-life treatment) from a corpus of scientific literature.
- Materials:
- Hardware: A standard high-performance computing workstation with a GPU (e.g., NVIDIA A100 with 40GB+ VRAM) is recommended for model fine-tuning and inference.
- Software: Python 3.8+, PyTorch or TensorFlow, Hugging Face Transformers library, and the "Sustain-LLaMA" framework code.
- Model: The LLaMA-2-7B model is used as the base architecture.
- Data: A curated corpus of scientific literature (PDFs or plain text) relevant to the target domain (e.g., methanol production).
- Procedure:
- Document Classification:
- Fine-tune a classification model (e.g., a BERT-based classifier) on a labeled dataset to identify and filter documents that are relevant to the LCA inquiry from a larger corpus.
- Validate the model's performance on a held-out test set, aiming for a high accuracy (e.g., >0.85) [22].
- Domain Knowledge Injection (Pre-training):
- Pre-train the base LLaMA-2-7B model on the selected, relevant texts from Step 1. This step injects specialized domain knowledge into the LLM's parameters.
- Question-Answering Model Fine-Tuning:
- Further fine-tune the pre-trained model from Step 2 on a custom Question-Answering (Q&A) task using a dataset of questions and answers derived from the literature.
- Implement a Retrieval Augmented Generation (RAG) architecture. The RAG system retrieves relevant text snippets from the corpus and conditions the LLM on them to generate accurate, evidence-backed answers.
- Validation and Benchmarking:
- Evaluate the final Q&A model's performance using metrics like the F1 score (target: >0.82) [22].
- Benchmark the model's accuracy and efficiency against baseline models, such as the vanilla LLaMA-2-7B without retraining, and general-purpose LLMs like ChatGPT-4o.
- Document Classification:
This framework demonstrates that a retrained LLM can achieve high accuracy in extracting complex environmental data, offering a scalable and precise tool for automating literature mining in chemical LCA research [22].
Workflow Visualization
The logical workflow for the Sustain-LLaMA protocol is outlined in the diagram below.
Figure 1: Sustain-LLaMA Workflow for LCI Data Retrieval from Literature.
Application Note: DrugGPT for Faithful Drug Analysis
In the context of drug development and target evaluation, the application of general-purpose LLMs is hindered by their tendency to produce "hallucinations"—factually incorrect but plausible-sounding content. The DrugGPT model was developed to address this critical challenge by ensuring recommendations are accurate, evidence-based, and traceable [39].
Experimental Protocol for Clinical-Quality Drug Analysis
This protocol outlines the methodology for building and evaluating a collaborative LLM for drug-related tasks, based on the DrugGPT framework [39].
- Objective: To provide accurate, evidence-based, and faithful answers to inquiries on drug recommendation, dosage, adverse reactions, drug-drug interactions, and general pharmacology questions.
- Materials:
- Knowledge Bases: Drugs.com, UK National Health Service (NHS), and PubMed.
- Base Models: Three instances of a general-purpose LLM (e.g., based on architectures like GPT or PaLM) to serve as the collaborative components.
- Datasets: For evaluation, use established benchmarks such as MedQA-USMLE, MedMCQA, ADE-Corpus-v2, DDI-Corpus, and PubMedQA [39].
- Procedure:
- Knowledge Base Integration:
- Construct a large medical knowledge graph (e.g., a Disease-Symptom-Drug Graph or DSDG) from the incorporated knowledge bases to model relationships between key entities.
- Implement Collaborative Mechanism:
- Inquiry Analysis LLM (IA-LLM): Implement this component using Chain-of-Thought (CoT) and few-shot prompting strategies to analyze user inquiries and determine what knowledge is required.
- Knowledge Acquisition LLM (KA-LLM): Use knowledge-based instruction prompt tuning to enable this component to efficiently extract relevant information from the knowledge bases and the DSDG.
- Evidence Generation LLM (EG-LLM): Employ CoT prompting, along with knowledge-consistency and evidence-traceable prompting, to generate the final answer based only on the evidence identified by the KA-LLM.
- Model Evaluation:
- Test the collaborative DrugGPT model on the designated downstream datasets.
- For multiple-choice tasks (e.g., MedQA), report accuracy. For recommendation tasks (e.g., ChatDoctor), calculate recall, precision, and F1 scores.
- Compare performance against a range of existing LLMs (e.g., GPT-4, ChatGPT, Med-PaLM-2).
- Knowledge Base Integration:
This structured approach ensures that the model's outputs are grounded in verified knowledge sources, making them suitable for clinical decision-making support [39].
Workflow Visualization
The collaborative mechanism of DrugGPT is illustrated in the following diagram.
Figure 2: DrugGPT Collaborative Model for Evidence-Based Drug Analysis.
The Scientist's Toolkit: Essential Research Reagents & Solutions
The implementation of the protocols described above relies on a suite of computational tools and data resources. The following table details these key components.
Table 2: Key Research Reagents and Solutions for LLM-Based Review Automation
| Item Name | Type | Function/Application | Example/Note |
|---|---|---|---|
| LLaMA-2-7B | Base Language Model | A publicly available, efficient large language model architecture that serves as a foundation for domain-specific fine-tuning [22]. | Used as the base model in the Sustain-LLaMA framework [22]. |
| Drugs.com Database | Knowledge Base | Provides comprehensive, up-to-date drug information for grounding LLM responses and preventing hallucinations in clinical recommendations [39]. | One of the primary knowledge sources integrated into DrugGPT [39]. |
| PubMed | Literature Database | A vast repository of biomedical literature used for retrieving primary studies and as a source of domain knowledge for pre-training LLMs [38] [39]. | Used for knowledge injection in Sustain-LLaMA and as a source for DrugGPT [22] [39]. |
| MedQA-USMLE Dataset | Benchmarking Dataset | A high-quality dataset of medical exam questions used to evaluate the performance and accuracy of LLMs on complex, clinically relevant reasoning tasks [39]. | Used to benchmark DrugGPT's performance against other models and human experts [39]. |
| Retrieval Augmented Generation (RAG) | Software Architecture | Enhances an LLM's responses by first retrieving relevant information from a knowledge source, then generating answers based on that evidence. This improves factual accuracy and traceability [22]. | Implemented in the Sustain-LLaMA Q&A model to improve precision [22]. |
| Chain-of-Thought (CoT) Prompting | Methodology | A prompting technique that encourages the LLM to break down its reasoning into intermediate steps, significantly improving its performance on complex logical tasks [39]. | Employed in the IA-LLM and EG-LLM components of the DrugGPT framework [39]. |
The application of Large Language Models (LLMs) in chemical Life Cycle Assessment (LCA) research represents a paradigm shift in how researchers, scientists, and drug development professionals approach carbon footprinting. Traditional LCA methodologies for chemicals face significant challenges, including data-intensive requirements, slow speed, and high costs that hinder rapid environmental impact assessment [30]. LLM-based frameworks now offer transformative potential by automating the retrieval of life cycle inventory (LCI) data and generating product carbon footprints (PCFs) with unprecedented efficiency. These AI-augmented approaches can accelerate sustainability assessments across chemical production and pharmaceutical development pipelines, enabling data-driven decisions that align with growing regulatory pressures and corporate climate commitments.
Experimental Protocols & Methodologies
Sustain-LLaMA Framework for LCI Data Retrieval
Protocol Objective: Automate extraction of life cycle inventory and environmental impact data from scientific literature to overcome manual data collection barriers.
Materials & Setup:
- Base Model: LLaMA-2-7B architecture
- Training Data: Domain-specific scientific literature on chemical processes
- Computational Environment: GPU-accelerated computing infrastructure
- Validation Dataset: USLCI database records for benchmark comparison
Methodological Steps:
- Document Classification: A fine-tuned classification model identifies relevant scientific documents with demonstrated accuracy of 0.850 for methanol production and 0.952 for plastic packaging end-of-life treatment [22].
- Domain Knowledge Integration: The base LLaMA-2-7B model undergoes pretraining on selected scientific texts to inject specialized chemical LCA knowledge.
- Data Extraction: A question-answering model fine-tuned with Retrieval Augmented Generation (RAG) architecture extracts specific LCI and environmental impact data.
- Validation & Benchmarking: Outputs are validated against established databases (USLCI) and compared with general-purpose models (ChatGPT-4o) using F1-score metrics.
Performance Metrics: The framework achieves F1 scores of 0.823 for methanol production and 0.855 for plastic packaging studies, demonstrating superior or comparable accuracy to existing approaches while significantly reducing processing time [22].
AI-Augmented Product Carbon Footprinting
Protocol Objective: Automate carbon accounting for chemical products across their entire life cycle.
Materials & Setup:
- Platform: Cloud-based carbon intelligence software (e.g., pacemaker.ai)
- Data Inputs: Bill of Materials (BOM), logistics data, Scope 1 and 2 emissions
- Emission Factors: Database of >30,000 emission factors from sources including ecoInvent and EXIOBASE
- Validation: ISO 14067 validation framework by GUTCert
Methodological Steps:
- Data Ingestion: Input BOMs, logistics information, and operational emissions data through simplified interfaces.
- Intelligent Mapping: Apply LLMs with advanced natural language processing capabilities to understand BOM contents and automatically assign appropriate emission factors.
- Multi-modal Calculation: Integrate transportation emissions using EcoTransit for precise logistics carbon accounting.
- Allocation & Reporting: Apply ISO 14067 emissions allocation model for Scope 1, 2, and 3.1 emissions, generating exportable PCF certificates.
Performance Metrics: This approach eliminates manual data collection and analysis, enabling scalable assessments for millions of products while maintaining compliance with international standards [40].
Molecular-Structure-Based Machine Learning for Rapid Impact Prediction
Protocol Objective: Predict life-cycle environmental impacts of chemicals directly from molecular structures.
Materials & Setup:
- Input Data: Chemical structures and molecular descriptors
- Training Data: Existing LCA databases for chemicals
- Model Architecture: Molecular-structure-based machine learning algorithms
- Validation: Cross-validation against traditional LCA results
Methodological Steps:
- Feature Engineering: Identify molecular features most pertinent to LCA results.
- Model Training: Train machine learning models on established chemical LCA datasets.
- Impact Prediction: Deploy models for rapid environmental impact estimation of new chemicals.
- Integration: Combine with LLMs for enhanced database building and feature engineering.
Performance Metrics: This approach addresses the critical challenge of data shortages in chemical LCA and enables rapid screening of chemical environmental impacts during early development phases [30].
Quantitative Performance Data
Table 1: Performance Metrics of AI-Based Carbon Footprinting Approaches
| Methodology | Accuracy/Quality Metrics | Processing Efficiency | Application Scope |
|---|---|---|---|
| Sustain-LLaMA Framework | F1 scores: 0.823 (methanol), 0.855 (plastic packaging) [22] | Automated data retrieval vs. manual literature review | LCI data extraction from scientific literature |
| AI-Augmented PCF Generation | ISO 14067 compliant; >30,000 emission factors [40] | Scalable to millions of products; eliminates manual data collection | Product carbon footprinting across supply chains |
| General Purpose LLMs in LCA | 37% of responses contain inaccuracies without grounding [41] | Quality explanations and labor reduction for simple tasks | Broad LCA task support with expert oversight |
| Molecular-Structure-Based ML | Addresses data shortage challenges [30] | Rapid prediction vs. traditional LCA | Chemical environmental impact screening |
Table 2: Expert Evaluation of LLM Performance on LCA Tasks
| Evaluation Criteria | Performance Rating | Key Findings |
|---|---|---|
| Scientific Accuracy | Mixed (37% inaccurate without grounding) [41] | Hallucination rates up to 40% for citations |
| Quality of Explanation | "Average" to "Good" across models [41] | Helpful for simplifying complex LCA concepts |
| Format Adherence | Generally favorable [41] | Good compliance with reporting structures |
| Robustness & Verifiability | Requires improvement [41] | Grounding mechanisms essential for credibility |
Workflow Visualization
AI-Augmented LCA Workflow: This diagram illustrates the integrated workflow combining LLM-based data acquisition, machine learning analysis, and expert validation for comprehensive chemical life cycle assessment.
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Resources for AI-Augmented Chemical LCA Research
| Resource/Platform | Type | Primary Function | Application Context |
|---|---|---|---|
| Sustain-LLaMA | Fine-tuned LLM | Extraction of LCI data from literature | Automated literature mining for chemical LCA data [22] |
| pacemaker.ai | Cloud-based Platform | Automated product carbon footprinting | ISO-compliant PCF generation for chemical products [40] |
| ecoInvent Database | Emission Factor Repository | Source of validated emission factors | Ground truth data for AI model training and validation [40] |
| LLaMA-2-7B | Base LLM Architecture | Foundation for domain-specific fine-tuning | Building specialized chemical LCA assistants [22] |
| RAG Pipeline | AI Framework | Retrieval Augmented Generation | Enhancing LLM accuracy with external knowledge bases [41] |
| Carbonpunk | AI-driven Carbon Management | Enterprise emissions tracking | Supply chain carbon accounting for pharmaceutical companies [42] |
Discussion & Implementation Guidelines
The integration of LLMs into chemical LCA practice offers substantial efficiency gains but requires careful implementation to mitigate risks. The expert-grounded benchmark reveals that 37% of LLM-generated responses contain inaccuracies when models operate without proper grounding mechanisms [41]. This underscores the critical importance of maintaining human expert oversight in the AI-augmented LCA pipeline.
Successful implementation requires a scaffolded approach where LLMs function as controlled language engines grounded in vetted corpora rather than as autonomous oracles. The Parakeet system operationalizes this through RAG architecture that embeds product descriptions, retrieves candidate emission factors from curated repositories, and maintains human-in-the-loop adjudication [41]. This division of labor leverages AI for scalability while preserving expert judgment for quality control.
For drug development professionals, these automated inventory generation approaches enable rapid environmental screening of chemical candidates early in the research pipeline. Molecular-structure-based machine learning provides particularly promising avenues for predicting environmental impacts before synthesis, potentially redirecting development toward more sustainable alternatives [30].
Future directions should focus on expanding the dimensions of predictable chemical life cycles, establishing larger open LCA databases for model training, and developing more efficient chemical descriptors specifically optimized for environmental impact prediction. The integration of LLMs is expected to provide further impetus for database building and feature engineering, ultimately creating a virtuous cycle of improved data resources and more accurate AI models [30].
The "Biologist-in-the-Loop" model represents a transformative approach in computational biology and drug discovery, positioning artificial intelligence as a powerful augmentative tool to human expertise rather than a replacement. This collaborative framework harnesses the ability of Large Language Models (LLMs) to process and synthesize vast amounts of scientific literature, thereby accelerating the research process while ensuring that critical decision-making remains guided by biological intuition and domain knowledge [43]. Within the context of chemical life cycle assessment and drug development, this model addresses a fundamental bottleneck: the extensive literature review that biologists must perform to validate novel biological hypotheses, such as new therapeutic targets [43]. By integrating LLMs that are trained on massive scientific corpora, researchers can instantaneously gather and summarize relevant information, allowing them to dedicate more time to experimental design and result interpretation. This synergy between human cognitive strengths and AI's computational power is particularly valuable in fields like sustainable chemistry and pharmacometrics, where data complexity and volume increasingly exceed unaided human processing capabilities [44] [45].
Table 1: Core Components of the Biologist-in-the-Loop Model
| Component | Description | Function in Research Workflow |
|---|---|---|
| AI Partner | LLM trained on scientific literature and data | Rapid information retrieval, summarization, and hypothesis generation |
| Domain Expert | Biologist, chemist, or drug development professional | Critical evaluation, experimental design, and final decision-making |
| Interface Tools | Retrieval-Augmented Generation (RAG) systems, APIs | Ensuring output accuracy and traceability to source literature |
| Validation Framework | Iterative feedback mechanisms | Continuous improvement of AI outputs through expert correction |
Fundamental Mechanisms: How LLMs Process Scientific Information
To understand the biologist-in-the-loop model's implementation, one must first grasp the fundamental mechanisms by which LLMs process and generate scientific information. LLMs are deep neural networks trained on massive text datasets, designed to comprehend, generate, and respond to human-like text through a self-supervised learning process of next-word prediction [44]. The process begins with tokenization, where input text is split into basic units (tokens) that are converted to integers and then to embedding vectors—dense representations that capture semantic relationships between words [44]. These embeddings, combined with positional encoding to maintain word order, are processed through transformer architectures that utilize attention mechanisms to weigh the relevance of different input tokens simultaneously, enabling the model to capture long-range dependencies in text more effectively than previous sequential models [44].
Two technical approaches particularly relevant to scientific applications are Retrieval-Augmented Generation (RAG) and Fine-tuning. RAG enhances LLM responses by first retrieving relevant documents from external knowledge bases (like PubMed) before generating answers, thereby grounding responses in citable sources and reducing hallucination [44] [46]. Fine-tuning involves additional training of a pre-trained LLM on domain-specific datasets, enhancing its performance on specialized tasks. The context window (ranging from ~8K to 1 million tokens in modern LLMs) determines how much preceding text the model can consider when generating responses, with larger windows enabling more comprehensive analysis of lengthy documents [44]. Temperature scaling controls output randomness, with lower values (closer to 0) producing more predictable, conventional outputs suitable for structured scientific reporting, while higher values (closer to 1) encourage more diverse and creative responses beneficial for hypothesis generation [44].
Diagram 1: RAG Workflow for Scientific Query
Application Protocols in Drug Discovery and Chemical Life Cycle Assessment
Protocol 1: Automated Literature Review for Target Validation
Purpose: To accelerate the initial validation of novel therapeutic targets or chemical compounds by rapidly synthesizing relevant scientific literature.
Background: Identifying and validating therapeutic targets is a critical bottleneck in drug discovery, traditionally requiring biologists to dedicate considerable time to literature review based on prior knowledge [43]. This protocol leverages LLMs to significantly speed up this process while maintaining scientific rigor through traceable source documentation.
Table 2: Performance Metrics of LLM-Assisted Literature Review
| Metric | Traditional Approach | LLM-Assisted Approach | Improvement |
|---|---|---|---|
| Time for initial literature synthesis | 5-10 business days | 1-2 business days | 70-85% faster |
| Number of papers reviewed in initial assessment | 20-30 papers | 100-200 papers | 5x increase |
| Consistency of analysis across targets | Variable (analyst-dependent) | High (standardized queries) | More consistent |
| Source traceability | Manual citation tracking | Automated source highlighting | Enhanced reproducibility |
Materials:
- LLM Platform: Access to a capable LLM (e.g., GPT-4, domain-specific models like BioBERT [44])
- Literature Databases: PubMed API access, proprietary chemical databases
- Query Formulation Framework: Structured question templates for consistent information extraction
- Validation Checklist: Expert-defined criteria for target assessment
Procedure:
- Question Design: Expert biologists formulate specific scientific questions to evaluate target quality (e.g., "Which pathway is target X involved in and what is its role?" "What is the evidence for target X in disease Y?") [43].
- Query Execution: Implement automated queries to PubMed API using carefully crafted, question-specific searches.
- Abstract Collection: Systematically gather relevant literature abstracts based on search results.
- LLM Processing: For each selected abstract, the LLM generates a concise response to the original scientific question.
- Summary Generation: The LLM synthesizes responses from individual abstracts into a consolidated answer providing a comprehensive picture.
- Source Annotation: The system highlights specific sources and data points that support its answers, enabling traceability.
- Expert Review: Biologists review the synthesized information, with the ability to drill down into original sources as needed.
Troubleshooting:
- For overly broad summaries: Refine question specificity and implement iterative questioning.
- For missing key studies: Adjust search parameters and implement synonym expansion in queries.
- For potential hallucination: Implement source verification protocols and cross-checking mechanisms.
Protocol 2: Active Learning for Target Label Enhancement
Purpose: To improve the quality of target labels for predictive models in drug discovery through an iterative human-AI collaboration process.
Background: High-quality labels for targets (both positive and negative examples) are scarce, with less than 1,000 of the ~20,000 protein-coding genes currently targeted by drugs, and underreporting of failed targets [43]. This protocol uses an active learning strategy to enhance label curation.
Materials:
- TargetMATCH or Similar AI Engine: For generating initial target rankings [43]
- Uncertainty Sampling Framework: Algorithm to identify ambiguous cases
- Labeling Interface: Tool for expert review and label assignment
- Feedback Integration System: Mechanism to incorporate expert feedback into models
Procedure:
- Initial Ranking: Generate target rankings using the AI pipeline (e.g., TargetMATCH).
- Uncertainty Identification: Apply uncertainty sampling to identify:
- False positives: Targets highly ranked by the algorithm but without clinical trial history
- False negatives: Targets ranked low but with clinical trial history [43]
- Literature Synthesis: Feed these target-indication pairs to the LLM summary tool to instantaneously gather relevant literature.
- Automated Label Generation: LLM automatically generates preliminary labels (good/bad/risky) and flags based on literature evidence.
- Expert Validation: Biomedical experts validate AI-generated labels and flags.
- Model Refinement: Incorporate validated labels as additional scores and filters in the predictive pipeline.
- Iterative Improvement: Repeat the process to continuously refine the AI algorithm's target predictions.
Troubleshooting:
- For inconsistent labels: Establish clearer labeling guidelines and implement cross-expert validation.
- For model instability: Implement gradual integration of new labels and monitor performance metrics.
- For confirmation bias: Include diverse expert perspectives and blind review protocols where appropriate.
Diagram 2: Active Learning for Target Labels
Protocol 3: Chemical Life Cycle Assessment Integration
Purpose: To incorporate sustainability assessments into early-stage drug development and chemical research using LLM-assisted life cycle assessment (LCA).
Background: Traditional LCA is labor-intensive, static, and often delayed, making it challenging to incorporate dynamic environmental impact considerations into research decisions [45] [47]. This protocol leverages LLMs to automate and update LCAs in near real-time, enabling researchers to balance performance, cost, and environmental impact in their decisions.
Materials:
- LCA Databases: Access to Ecoinvent, GaBi, or similar LCI databases [47]
- Chemical Process Data: Information on synthesis pathways, raw materials, and energy requirements
- Environmental Impact Models: LCIA methods for calculating various environmental impact categories
- LLM Integration Framework: System for querying and synthesizing LCA information
Procedure:
- Goal and Scope Definition: Use LLMs to help define appropriate system boundaries and assessment parameters based on the chemical compound or process under investigation.
- Inventory Automation: Implement LLM-powered data extraction from scientific literature, patents, and technical reports to compile life cycle inventory data.
- Impact Assessment: Utilize LLMs to assist in selecting appropriate impact assessment methods and interpreting characterization factors.
- Dynamic Updating: Establish protocols for updating LCA results as formulations, suppliers, or regulations change.
- Scenario Analysis: Employ LLMs to generate and evaluate alternative synthesis pathways or material substitutions for improved sustainability.
- Interpretation and Reporting: Use LLMs to help synthesize findings and generate comprehensive reports linking chemical decisions to environmental outcomes.
Troubleshooting:
- For data quality issues: Implement validation checks and uncertainty assessments.
- For methodological inconsistencies: Establish standardized protocols and cross-method comparisons.
- For computational complexity: Implement modular assessments and prioritized impact categories.
The Scientist's Toolkit: Essential Research Reagents and Solutions
Table 3: Key Research Reagents and Computational Tools for LLM-Enhanced Research
| Tool/Reagent | Type | Function | Example Applications |
|---|---|---|---|
| TargetMATCH | AI Engine | Identifies candidate targets and patient subgroups | Prioritizing therapeutic targets based on multimodal patient data [43] |
| RAG Framework | LLM Enhancement | Grounds LLM responses in retrievable sources | Literature synthesis for target validation [43] [46] |
| SPIRES Method | Data Extraction | Extracts structured data from scientific literature | Converting unstructured research findings into analyzable data [46] |
| PubChem API | Chemical Database | Provides chemical structure and property data | Assessing compound characteristics and similarities |
| Ecoinvent Database | LCA Database | Contains life cycle inventory data | Environmental impact assessment of chemical processes [47] |
| Uncertainty Sampling | Active Learning | Identifies ambiguous cases for expert review | Improving target label quality through focused expert attention [43] |
| Chain-of-Thought Prompting | LLM Technique | Guides step-by-step reasoning in models | Complex problem-solving and experimental design [44] |
Implementation Framework and Best Practices
Successful implementation of the biologist-in-the-loop model requires careful attention to workflow design, validation protocols, and ethical considerations. The framework should ensure that human insight and control are retained throughout the research process [31]. Key implementation considerations include:
Workflow Integration: The LLM tools should be seamlessly integrated into existing research workflows rather than requiring significant process changes. This includes compatibility with laboratory information management systems (LIMS), electronic lab notebooks, and data analysis platforms.
Validation Protocols: Establish rigorous validation procedures including:
- Source traceability for all LLM-generated content
- Cross-validation with known biological knowledge
- Experimental verification of key predictions
- Peer review of AI-assisted findings
Bias Mitigation: Implement strategies to identify and address potential biases in both training data and expert perspectives, including:
- Diverse data source integration
- Multi-expert review systems
- Transparent documentation of limitations
Performance Monitoring: Continuously assess the impact of LLM integration on research outcomes through metrics such as:
- Time from hypothesis to experimental design
- Target validation accuracy rates
- Resource utilization efficiency
- Reproducibility of findings
The biologist-in-the-loop model represents a paradigm shift in how scientific research is conducted, creating a collaborative partnership between human expertise and artificial intelligence that enhances both productivity and innovation in drug discovery and chemical life cycle assessment.
Retrieval-Augmented Generation (RAG) for Grounded Emission Factor Selection
Accurately quantifying greenhouse gas (GHG) emissions is crucial for organizations to measure and mitigate their environmental impact. Life cycle assessment (LCA) estimates these environmental impacts throughout a product's entire lifecycle, from raw material extraction to end-of-life [48]. A critical challenge in LCA is selecting appropriate emission factors (EFs)—estimations of GHG emissions per unit of activity—to model and estimate indirect impacts [48]. The current practice of manually selecting EFs from databases is time-consuming, error-prone, and requires significant expertise [48].
Retrieval-Augmented Generation (RAG) addresses key limitations of standalone Large Language Models (LLMs) by incorporating external, real-time information retrieval to ground responses in verified data [49]. This approach is particularly valuable in chemical and materials science research, where safety considerations and precision are paramount [50]. For chemical LCA research, RAG systems can integrate domain-specific databases, scientific literature, and emission factor repositories to provide accurate, context-aware EF recommendations with human-interpretable justifications.
Quantitative Performance Evaluation
Benchmarking across multiple real-world datasets demonstrates that AI-assisted EF recommendation methods achieve high precision in both fully automated and assisted decision-making scenarios.
Table 1: Performance Metrics for Automated EF Recommendation Systems
| Performance Scenario | Average Precision | Key Characteristics |
|---|---|---|
| Fully Automated(Top recommendation selected as final) | 86.9% [48] | • Minimal human intervention• Highest efficiency gain• Suitable for high-confidence matches |
| Assisted Selection(Correct EF appears in top 10 recommendations) | 93.1% [48] | • Preserves expert oversight• Reduces search space by ~90%• Balances automation with control |
These results indicate that AI-assisted methods can streamline EF selection while maintaining high accuracy, enabling scalable and accurate quantification of GHG emissions to support sustainability initiatives across industries [48].
Implementation Framework
Multi-Component RAG Architecture
Advanced RAG frameworks for scientific domains like emission factor selection employ sophisticated retrieval and filtering components to ensure recommendation accuracy. The MAIN-RAG framework exemplifies this approach with its multi-agent filtering system that leverages multiple LLM agents to collaboratively filter and score retrieved documents [49]. This system introduces an adaptive filtering mechanism that dynamically adjusts relevance filtering thresholds based on score distributions, effectively minimizing noise while maintaining high recall of relevant documents [49].
Table 2: Essential Components for RAG-based EF Selection Systems
| Component Category | Specific Tools/Techniques | Function in EF Selection |
|---|---|---|
| Core AI Models | • Transformer-based LLMs• Sentence-BERT (SBERT) embeddings [51] | • Natural language understanding• Semantic similarity calculation• Contextual reasoning about EF applicability |
| Retrieval Enhancement | • Multi-agent filtering (MAIN-RAG) [49]• Adaptive relevance thresholds [49] | • Quality control of retrieved documents• Noise reduction in EF databases• Dynamic precision-recall balancing |
| Knowledge Representation | • Knowledge Graphs (KGs) [52]• Directed Acyclic Graphs (DAGs) [51] | • Modeling process relationships in LCA• Structuring product lifecycle information• Capturing EF dependencies and contexts |
| Domain Data Sources | • LCA databases (e.g., EPD International) [51]• Chemical-specific EF repositories• Scientific literature (via PubMed, etc.) [48] | • Providing verified EF values• Contextual LCA process information• Domain-specific validation sources |
Workflow Protocol for EF Selection
The following workflow provides a detailed, implementable protocol for deploying RAG systems to grounded emission factor selection in chemical LCA research.
Phase 1: Query Processing
- Input Requirements: Collect detailed product/process description including materials, manufacturing methods, energy sources, and transportation details.
- Semantic Enhancement: Expand query using domain-specific ontologies from chemical LCA taxonomy [51]. Incorporate terminology from UNCPC descriptions and relevant product category rules.
- Embedding Generation: Convert enhanced query to vector representation using Sentence-BERT (SBERT) or similar embedding model optimized for scientific texts [51].
Phase 2: Retrieval & Filtering
- Multi-Source Retrieval: Query structured LCA databases (e.g., EPD International [51]), scientific literature (e.g., PubMed [48]), and emission factor repositories simultaneously.
- Multi-Agent Filtering: Deploy multiple LLM agents with specialized roles (precision-focused, recall-focused, domain-expert) to evaluate document relevance [49]. Each agent scores retrieved documents independently.
- Consensus-Based Selection: Apply adaptive thresholding to select documents based on inter-agent consensus scores, prioritizing documents with high agreement for relevance [49].
Phase 3: Generation & Validation
- Context-Enabled Generation: Feed filtered documents to LLM with instructions to generate EF recommendations specifically for the query context. Include temperature parameter set low (0.1-0.3) to reduce creativity and increase consistency.
- Uncertainty Quantification: Generate confidence scores for each recommendation based on source quality, recency, and contextual alignment. Flag recommendations with conflicting source information.
- Ranked Output Delivery: Present final output as ranked list of up to 10 EF recommendations with justifications, confidence scores, and source references for expert validation [48].
Integration with Active LCA Environments
For optimal performance in chemical LCA research, RAG systems should be deployed in "active" rather than "passive" environments [50]. Active environments enable LLMs to interact with databases and instruments to gather real-time information, as opposed to merely responding based on training data [50]. This distinction is crucial in chemistry where hallucinated synthesis procedures or outdated information can lead to serious safety hazards or environmental risks [50].
Implementation requires connecting the RAG system to:
- Real-time chemical databases and LCA repositories
- Computational chemistry software for property verification
- Laboratory information management systems (LIMS) for experimental data
- Cloud-based instrument control systems for validation
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Components for Implementing RAG-based EF Selection
| Tool/Component | Function in RAG System | Implementation Notes |
|---|---|---|
| Domain-Specific Embeddings (e.g., Sentence-BERT [51]) | Encodes text queries into vector representations for semantic similarity search | Fine-tune on chemical/LCA corpora for improved domain understanding |
| Knowledge Graph Framework [52] | Structures lifecycle inventory data and EF relationships as interconnected triples | Use labeled property graphs (LPGs) for efficient storage and rapid traversal [52] |
| Multi-Agent Filtering System (MAIN-RAG) [49] | Reduces noise in retrieved documents through collaborative agent scoring | Implement 3+ specialized agents with different relevance perspectives [49] |
| Adaptive Threshold Mechanism [49] | Dynamically adjusts filtering strictness based on score distributions | Prevents both excessive strictness and permissiveness in document selection |
| LCA Database Connectors | Interfaces with specialized databases (e.g., EPD International [51]) | Use API access where available; web scraping with respect to terms of service |
| Uncertainty Quantification Module | Calculates confidence scores for EF recommendations | Consider source authority, temporal relevance, and contextual alignment factors |
RAG systems represent a transformative approach to emission factor selection in chemical life cycle assessment research. By integrating the structured knowledge of LCA databases with the reasoning capabilities of large language models, these systems achieve an optimal balance between automation and accuracy. The multi-agent filtering approach maintains high precision (86.9% in fully automated mode [48]) while minimizing the risks of hallucination that are particularly concerning in chemical applications [50].
Future development should focus on expanding the knowledge graph infrastructure to better model complex chemical processes [52], enhancing multi-modal capabilities to interpret spectral and structural data [53], and improving temporal reasoning to account for evolving emission factors and regulatory standards. As these systems mature, they will play an increasingly vital role in supporting accurate, scalable environmental impact assessments and advancing sustainability initiatives across the chemical and pharmaceutical industries.
Large language models (LLMs) are revolutionizing pharmaceutical research by introducing advanced capabilities for understanding and generating complex scientific language. Within the context of chemical life cycle assessment (LCA) research, these models offer transformative potential for accelerating and refining drug discovery and development processes. The integration of LLMs spans the entire pharmaceutical pipeline, from initial target identification through clinical trial analysis, while simultaneously addressing growing concerns about the environmental sustainability of drug development. By applying specialized or general-purpose LLMs to biomedical data, researchers can uncover novel disease mechanisms, design optimized drug candidates, and streamline clinical research processes, thereby reducing both the temporal and resource burdens traditionally associated with bringing new therapies to market [54]. This application note details specific use cases, provides validated experimental protocols, and presents quantitative performance data to guide researchers in implementing LLMs within their drug development workflows.
LLM Applications Across the Drug Development Pipeline
The drug development pipeline is traditionally categorized into three core stages: understanding disease mechanisms, drug discovery, and clinical trials. LLMs contribute uniquely to each phase, with varying levels of maturity as summarized in Table 1 [54].
Table 1: Maturity Assessment of LLM Paradigms in Drug Development
| Development Stage | Downstream Task | Specialized LLMs | General-Purpose LLMs |
|---|---|---|---|
| Understanding Disease Mechanisms | Target-Disease Linkage | Advanced | Nascent |
| Functional Genomics Analysis | Advanced | Nascent | |
| Hypothesis Generation | Nascent | Nascent | |
| Drug Discovery | De Novo Molecule Design | Advanced | Nascent |
| ADMET Prediction | Advanced | Not Applicable | |
| Automated Chemistry | Nascent | Advanced | |
| Clinical Trials | Patient-Trial Matching | Not Applicable | Advanced |
| Endpoint Prediction | Not Applicable | Nascent | |
| Trial Design Optimization | Not Applicable | Nascent |
Specialized LLMs, trained on domain-specific data like molecular SMILES strings or protein FASTA sequences, excel in tasks such as target identification and molecule design [54]. In contrast, general-purpose LLMs like GPT-4 demonstrate emerging capabilities in reasoning and planning, making them suitable for automating clinical trial workflows and analyzing scientific literature [54]. A hybrid approach often yields the best results, combining the strengths of both paradigm types.
Application Note & Protocol 1: Target Identification and Prioritization
Background and Utility
The initial stage of drug development requires identifying and validating biological targets linked to disease mechanisms. LLMs can accelerate this process by analyzing vast volumes of genomic data and scientific literature to pinpoint genes with desirable characteristics for drug targeting, drawing on both experimental data and existing publications [54]. This application is particularly valuable for life cycle assessment research as it enables more efficient and targeted research, potentially reducing the extensive resource consumption associated with exploratory phases.
Experimental Protocol
Objective: To identify and prioritize novel gene targets for a specified disease using LLM-driven analysis of functional genomics and biomedical literature.
Materials and Reagents:
- Hardware: Standard workstation with GPU acceleration (recommended for local models).
- Software: Python environment with necessary libraries (Transformers, PyTorch/TensorFlow).
- LLM Access: API or local access to a general-purpose LLM (e.g., GPT-4, LLaMA) and a specialized biomedical LLM (e.g., BioBERT, Geneformer).
- Data Sources: Public genomics databases (e.g., TCGA, GEO), scientific literature corpora (e.g., PubMed), and structured knowledge bases (e.g., UniProt, OMIM).
Methodology:
- Problem Formulation and Data Collection:
- Define the disease of interest and compile a list of candidate genes from genome-wide association studies (GWAS) or differential expression analyses.
- Gather relevant scientific abstracts and full-text articles pertaining to the candidate genes and the disease.
LLM-Based Literature Synthesis:
- Utilize a general-purpose LLM with a prompting strategy designed for evidence synthesis. The prompt should instruct the model to extract relationships between genes and diseases, summarize supporting evidence, and identify knowledge gaps.
- Sample Prompt: "Act as a biomedical researcher. For the gene list [Insert Gene List] and disease [Insert Disease Name], extract and summarize all causal, correlative, or functional relationships from the provided literature. For each relationship, indicate the strength of evidence and the source."
Functional Genomic Analysis:
- Employ a specialized LLM pre-trained on single-cell transcriptomes (e.g., Geneformer). Use the model to perform in silico perturbation experiments, such as simulating gene knockdowns to predict subsequent effects on transcriptional networks and disease-associated cellular states [54].
Target Prioritization and Ranking:
- Integrate the outputs from steps 2 and 3. Develop a scoring algorithm that weights criteria such as:
- Strength of LLM-identified evidence from literature.
- Predicted impact of perturbation from the functional genomics model.
- Druggability potential (e.g., presence of enzymatic domains, membrane receptors).
- Use the LLM to generate a final ranked list of targets with a justification for each ranking.
- Integrate the outputs from steps 2 and 3. Develop a scoring algorithm that weights criteria such as:
Validation: Experimentally validate top-ranked targets using in vitro models (e.g., cell-based assays) to confirm the predicted biological role in the disease context.
Application Note & Protocol 2: Automated Clinical Trial Feasibility Assessment
Background and Utility
Nearly 50% of clinical trials fail to meet recruitment goals, often due to overly restrictive or complex eligibility criteria [55]. LLMs can automate the transformation of free-text eligibility criteria into structured queries to run against real-world data (RWD), enabling rapid feasibility assessment and optimization of trial design [56] [55]. This application directly enhances the sustainability of clinical research by reducing the high failure rates that contribute significantly to the environmental footprint of drug development.
Experimental Protocol
Objective: To convert free-text clinical trial eligibility criteria from ClinicalTrials.gov into executable OMOP CDM-compatible SQL queries using an LLM-powered pipeline, and to evaluate the feasibility of patient recruitment.
Materials and Reagents:
- Hardware: Standard computer with internet access.
- Software: LLM API (e.g., OpenAI GPT-4, open-source alternatives like LLaMA), database management system (e.g., PostgreSQL), OMOP CDM database.
- Data Sources: AACT (Aggregate Analysis of ClinicalTrials.gov) database, institutional OMOP CDM database or synthetic dataset (e.g., SynPUF) for validation [55].
Methodology:
- Data Preprocessing:
- Segmentation: Split the free-text eligibility criteria into individual, self-contained statements.
- Filtration: Remove non-queryable criteria (e.g., "patient must provide informed consent").
- Simplification: Standardize temporal expressions and clinical phrases to reduce token count and complexity for the LLM. This step achieved a 58.2% token reduction in a validated study [55].
Information Extraction and Concept Mapping:
- Use the LLM to identify and extract key clinical concepts (e.g., "type 2 diabetes," "HbA1c > 7%") from each simplified criterion.
- Map these concepts to standardized OMOP CDM concept IDs. A study found GPT-4 achieved a 48.5% accuracy in this mapping task, significantly outperforming a rule-based system (32.0%) [55].
- Sample Prompt for Mapping: "Map the following clinical term to its correct OMOP CDM standard concept ID: '[Clinical Term]'. Return only the JSON object with fields 'term', 'concept_id', and 'domain'."
SQL Query Generation:
- Provide the LLM with the structured concept list and a schema of the OMOP CDM. Instruct it to generate a SQL query that identifies patients meeting all inclusion and no exclusion criteria.
- Critical Consideration: Hallucination of incorrect concept IDs is a major risk. One study reported an overall hallucination rate of 32.7%, with wrong domain assignments (34.2% of hallucinations) being the most common error [55]. Implement a validation loop to check generated concept IDs against the OMOP vocabulary.
Feasibility Analysis and Validation:
- Execute the validated SQL query on the OMOP CDM database to estimate the number of eligible patients.
- Clinically validate the results by manually reviewing a sample of patient records identified by the query to ensure accuracy. Performance varies by condition; one validation showed high concordance for type 1 diabetes (Jaccard=0.81) but complete failure for pregnancy criteria (Jaccard=0.00) [55].
Table 2: Performance and Hallucination Rates of Select LLMs in SQL Generation for Clinical Trials [55]
| LLM Model | Effective SQL Generation Rate | Hallucination Rate | Key Strengths/Weaknesses |
|---|---|---|---|
| GPT-4 | 45.3% | 33.7% | Good concept mapping accuracy (48.5%) but higher hallucination. |
| llama3:8b | 75.8% | 21.1% | Higher effective SQL rate, lower hallucination, cost-effective. |
| Other Open-Source Models | Variable (21-50%) | Variable (21-50%) | Model size does not necessarily correlate with performance. |
The workflow for this protocol is as follows:
Application Note & Protocol 3: Clinical Evidence Synthesis with AI Pipelines
Background and Utility
Systematic reviews of clinical literature are foundational for evidence-based medicine but are notoriously time-consuming and labor-intensive. LLM-powered pipelines like TrialMind can dramatically accelerate this process, reducing the time for study screening and data extraction while improving recall and accuracy compared to manual methods or standalone LLMs [57]. This enhances the reliability and speed of clinical evidence generation, which informs trial design and regulatory decisions, thereby improving the overall efficiency of the drug development life cycle.
Experimental Protocol
Objective: To utilize an LLM-driven pipeline (TrialMind) for automating the identification, screening, and data extraction phases of a systematic review for clinical evidence synthesis.
Materials and Reagents:
- Software: TrialMind pipeline or equivalent custom-built system leveraging LLMs (e.g., via API).
- LLM Access: High-performance general-purpose LLM such as GPT-4.
- Data Sources: PubMed database, target systematic review topic with defined PICO elements.
Methodology:
- Study Search (Identification):
- Input the PICO (Population, Intervention, Comparison, Outcome) elements of the research question into the TrialMind pipeline.
- The pipeline uses an LLM to generate, augment, and refine Boolean search queries for PubMed.
- Performance: This approach achieved an average recall of 0.782, significantly outperforming a baseline where GPT-4 was asked to generate queries directly (recall=0.073) and a human baseline (recall=0.187) [57].
Study Screening:
- The LLM ranks the thousands of citations retrieved from the search based on their likelihood of meeting the eligibility criteria for the review.
- The output is a prioritized list where the most relevant studies appear at the top, drastically reducing the manual screening burden.
- Performance: TrialMind outperformed previous document ranking methods by a 1.5 to 2.6-fold change [57].
Data Extraction:
- For each included study, the LLM extracts specific data points (e.g., study design, participant demographics, outcome measurements) from the full-text articles into a structured format.
- Performance: TrialMind's data extraction accuracy was 16-32% higher than GPT-4's alone. In a human-AI collaboration pilot, it increased expert accuracy by 23.5% while reducing data extraction time by 63.4% [57].
Table 3: Performance of TrialMind vs. Baselines in Evidence Synthesis [57]
| Task | Metric | TrialMind | GPT-4 Baseline | Human Baseline |
|---|---|---|---|---|
| Study Search | Average Recall | 0.782 | 0.073 | 0.187 |
| Study Screening | Fold improvement vs. previous methods | 1.5 - 2.6x | N/A | N/A |
| Data Extraction | Accuracy vs. GPT-4 | +16% to +32% | Baseline | N/A |
| Human-AI Collaboration | Time Reduction (Screening/Extraction) | 44.2% / 63.4% | N/A | Baseline |
The Scientist's Toolkit: Key Research Reagent Solutions
Table 4: Essential Resources for Implementing LLMs in Drug Development
| Tool / Resource | Type | Primary Function | Example Use Case |
|---|---|---|---|
| OMOP CDM | Data Standard | Provides a common data model for organizing healthcare data. | Enables standardized querying of electronic health records for trial feasibility [55]. |
| USAGI | Software Tool | Rule-based system for mapping clinical terms to OMOP vocabularies. | Serves as a benchmark for evaluating LLM performance in concept mapping [55]. |
| Geneformer | Specialized LLM | A transformer model pre-trained on single-cell transcriptomic data. | Performing in silico gene knockdowns to identify novel drug targets [54]. |
| TrialMind / Custom LLM Pipeline | Software Framework | An integrated system designed to automate systematic review tasks. | Accelerating clinical evidence synthesis from literature search to data extraction [57]. |
| SynPUF (Synthetic Public Use Files) | Data Source | A synthetic Medicare beneficiary dataset in OMOP CDM format. | Providing a safe, standardized test bed for developing and validating clinical trial queries without using real patient data [55]. |
| RAG (Retrieval-Augmented Generation) | Technical Method | Enhances LLMs by grounding them in external, verified knowledge bases. | Reducing hallucinations in LLM-generated outputs by providing access to current, structured data [58] [41]. |
The integration of large language models into drug development, from target identification to clinical trial analysis, marks a significant paradigm shift toward more efficient and data-driven research. The protocols and data presented herein demonstrate that LLMs can deliver substantial gains in speed and accuracy, whether in designing a clinical trial, synthesizing medical evidence, or discovering new therapeutic targets. However, challenges such as model hallucination, performance variability, and the need for rigorous human oversight remain. A hybrid approach, combining the strengths of specialized and general-purpose models within frameworks that prioritize human-AI collaboration and are grounded in high-quality data, presents the most promising path forward. By adopting these advanced tools, researchers and drug development professionals can not only accelerate the creation of new therapies but also contribute to a more sustainable and effective research life cycle.
Navigating Pitfalls: Mitigating Hallucinations, Bias, and Computational Limits
Large language models (LLMs) present a transformative opportunity to accelerate chemical life cycle assessment (LCA) research by rapidly processing vast scientific literature, generating life cycle inventory data, and interpreting complex environmental impact assessments [59] [22]. However, their integration into scientific workflows introduces substantial risks from model hallucinations—the generation of plausible but factually incorrect information, including synthetic citations, inaccurate numerical data, and unsubstantiated methodological recommendations [59] [41]. In chemical LCA contexts, where precise data and validated sources are essential, such inaccuracies can compromise research validity and lead to erroneous sustainability conclusions.
Recent expert-grounded benchmarking reveals the scope of this challenge: evaluations show that 37% of LLM responses to LCA-related tasks contain inaccurate or misleading information, with some models producing hallucinated citations at rates up to 40% [41]. The consequences are particularly severe in chemical research, where hallucinations might suggest unsafe synthesis procedures or incorrect environmental impact factors [60]. This application note establishes structured protocols to mitigate these risks while harnessing LLM capabilities for chemical LCA research.
Quantitative Landscape: Hallucination Prevalence and Impact
Table 1: Expert-Assessed LLM Performance on LCA Tasks
| Evaluation Metric | Performance Finding | Research Implications |
|---|---|---|
| Factual Accuracy | 37% of responses contained inaccurate/misleading information [41] | Compromised data quality in life cycle inventory development |
| Citation Integrity | Up to 40% hallucination rate for cited sources [41] | Undermines verification and reproducibility of LCA studies |
| Expert Agreement | Human experts agreed with LLM judgments 68% of the time [61] | Significant gap in domain-specific reasoning capability |
| RAG Effectiveness | F1 scores of 0.823-0.855 for domain-specific data retrieval [22] | Grounding strategies substantially improve output reliability |
Table 2: Hallucination Risk Assessment by LCA Phase
| LCA Phase | High-Risk Hallucination Types | Potential Impact Severity |
|---|---|---|
| Goal & Scope | Incorrect standards citation, inappropriate boundary recommendations | High - Affects entire study validity |
| Inventory Analysis | Fabricated emission factors, incorrect chemical properties | Critical - Directly alters results |
| Impact Assessment | Mischaracterized impact categories, erroneous characterization factors | High - Affects interpretation |
| Interpretation | Unsupported conclusions, inaccurate uncertainty assessment | Medium - Affects decision-making |
Core Mitigation Strategies: A Multi-Layer Framework
Retrieval-Augmented Generation (RAG) for Chemical LCA
Retrieval-Augmented Generation fundamentally alters how LLMs access information by grounding responses in verified external knowledge rather than relying solely on training data. This approach is particularly valuable for chemical LCA, where databases containing life cycle inventory data, emission factors, and chemical properties require precise recall [22].
The "Sustain-LLaMA" framework demonstrates RAG implementation for LCA data extraction, achieving F1 scores of 0.823-0.855 on technical literature by following a structured pipeline: fine-tuned document classification → domain-specific pretraining → question-answering with retrieval augmentation [22]. This system significantly outperforms base models without domain adaptation, proving particularly effective for extracting life cycle inventory data for methanol production and plastic packaging end-of-life treatment [22].
Active vs. Passive LLM Environments
Creating active environments where LLMs interact with external tools and databases represents a critical paradigm shift from passive question-answering systems. In chemical LCA research, this means integrating LLMs with laboratory instruments, chemical databases, computational software, and LCA-specific tools rather than treating them as isolated oracles [60].
Table 3: Comparison of LLM Deployment Environments for Chemical Research
| Environment Type | Key Characteristics | Hallucination Risk Level | Suitable LCA Tasks |
|---|---|---|---|
| Passive Environment | Relies solely on training data, no real-time verification | High | Preliminary literature scanning, template generation |
| Active Environment | Interfaces with databases, instruments, and analytical tools | Moderate to Low | Life cycle inventory development, impact factor calculation |
| Human-in-the-Loop | Integrates expert review at critical decision points | Low | Interpretation, uncertainty analysis, final reporting |
Research by Gomes and MacKnight demonstrates that active environments transform the researcher's role "from someone who executes experiments to more like a director of AI-driven discovery" [60]. This approach is particularly crucial for chemistry applications where safety considerations demand verification through specialized tools rather than model confidence alone [60].
Domain-Specific Fine-Tuning and Evaluation
General-purpose LLMs consistently underperform on chemical LCA tasks due to specialized terminology, precise numerical reasoning requirements, and complex technical contexts [41]. Domain-specific adaptation through fine-tuning on chemical literature and LCA methodology substantially reduces hallucination rates.
The expert-grounded benchmark of general-purpose LLMs in LCA revealed that "open-weight models outperformed or competed on par with closed-weight models on criteria such as accuracy and quality of explanation" when properly adapted to domain contexts [41]. This suggests that accessible models can achieve specialist-level performance with appropriate training strategies.
Experimental Protocols for Hallucination Mitigation
Protocol: RAG Implementation for Life Cycle Inventory Data Extraction
Purpose: To extract accurate life cycle inventory data from scientific literature while minimizing hallucination risks.
Materials:
- Scientific literature corpus (e.g., ACS Publications, Springer, LCA-specific journals)
- Pre-trained LLM (e.g., LLaMA-2-7B or similar open-weight model)
- Domain-specific datasets (e.g., USLCI, Ecoinvent, ChemBL)
- Computing environment with adequate GPU resources
Procedure:
- Corpus Preparation
- Collect and preprocess 5,000+ chemical LCA publications
- Annotate key data points: chemical properties, emission factors, process inputs/outputs
- Convert to searchable vector database with metadata tagging
Model Retraining
- Implement three-stage framework as described by Kumar et al. [22]:
- Stage 1: Fine-tuned classification model to identify relevant documents
- Stage 2: Domain-specific pretraining on selected chemical LCA texts
- Stage 3: Fine-tuned Q&A model with RAG capabilities
Validation and Testing
- Evaluate classification accuracy on unseen data (target: >0.85 accuracy)
- Assess Q&A performance using F1 scores (target: >0.80)
- Compare extracted data against verified databases (e.g., USLCI)
Expected Outcomes: The retrained "Sustain-LLaMA" model demonstrated classification accuracies of 0.850 for methanol production and 0.952 for plastic packaging studies, with Q&A F1 scores of 0.823 and 0.855 respectively [22].
Protocol: Active Environment Implementation for Chemical Assessment
Purpose: To create an integrated system where LLMs interact with chemical databases and analytical tools to verify outputs.
Materials:
- LLM API access (commercial or self-hosted)
- Chemical databases (PubChem, ChemSpider, NIST Chemistry WebBook)
- LCA software and databases (OpenLCA, Ecoinvent, GREET)
- Laboratory information management system (LIMS) access
Procedure:
- Tool Integration Design
- Map required verification sources for common chemical LCA queries
- Establish APIs between LLM interface and external databases
- Create verification protocols for numerical data and chemical properties
Workflow Implementation
- Design sequential verification steps for LLM-generated content
- Implement "read-back" protocols to confirm data accuracy
- Create automated flagging for outputs requiring expert review
Human-in-the-Loop Integration
- Identify critical decision points requiring expert validation
- Design interface for efficient expert review and correction
- Establish feedback mechanisms to improve system performance
Expected Outcomes: Research demonstrates that active environments fundamentally reduce hallucination risks by grounding responses in real-time data verification rather than training data recall [60]. This approach is particularly valuable for chemical safety assessments and emission factor development.
The Scientist's Toolkit: Essential Research Reagents
Table 4: Research Reagent Solutions for LLM Validation in Chemical LCA
| Tool/Resource | Function | Implementation Example |
|---|---|---|
| Domain-Specific Benchmarks (e.g., CURIE) | Evaluate scientific reasoning across materials science, quantum chemistry, and biodiversity [61] | Test model performance on post-training chemical data to verify reasoning, not recall |
| Retrieval-Augmented Generation (RAG) | Ground model responses in verified chemical databases and literature [22] | Implement vector databases of chemical LCA literature for real-time retrieval during response generation |
| Expert-in-the-Loop Protocols | Integrate human validation at critical decision points [41] [62] | Establish review checkpoints for emission factors, impact assessment choices, and interpretation |
| Chemical Database APIs | Verify model-generated data against authoritative sources [60] | Automated cross-referencing of suggested chemical properties against PubChem, NIST |
| Multi-Metric Evaluation Suites | Assess model performance beyond simple accuracy metrics [63] | Combine factual accuracy, citation integrity, reasoning transparency, and domain alignment |
Confronting LLM hallucinations in chemical life cycle assessment requires systematic implementation of verification strategies rather than relying on any single solution. The most effective approach combines retrieval-augmented generation to ground responses in verified knowledge, active environments that integrate laboratory tools and databases, and domain-specific adaptation to address the unique challenges of chemical research. Critically, these technical solutions must be embedded within research workflows that maintain human expertise as the ultimate validator of scientific outputs.
As Gomes emphasizes, "There is a common misconception that using large language models in research is like asking an oracle for an answer. The reality is that nothing works like that" [60]. By implementing the protocols and strategies outlined in this application note, chemical LCA researchers can harness the productivity benefits of LLMs while maintaining the factual integrity essential to credible environmental assessments.
Large Language Models (LLMs) possess a fundamental limitation known as a knowledge cutoff—a specific date after which the model has not been trained on new data [64]. In the dynamic field of chemical life cycle assessment (LCA) and drug development, where new compounds, synthesis pathways, and environmental impact data emerge constantly, this limitation poses significant risks. Relying on outdated information can lead to inaccurate carbon footprint calculations, flawed sustainability assessments, and compromised research conclusions.
Retrieval-Augmented Generation (RAG) has emerged as a powerful framework to address this challenge. RAG enhances LLMs at inference time by retrieving relevant, up-to-date information from external sources and providing it as context to the model, enabling the generation of responses that reflect the current state of knowledge [65] [64]. This approach is particularly vital for LCA research, where access to the latest scientific literature, life cycle inventory (LCI) databases, and regulatory information is crucial for accurate environmental impact evaluations of chemicals and pharmaceuticals.
Core Techniques for Real-Time Data Integration
Retrieval-Augmented Generation (RAG)
RAG operates through a sequential process that combines retrieval-based methods with generative AI. The system first processes a user's query to identify and fetch the most relevant information from a designated, up-to-date knowledge base. This retrieved context is then fed to the LLM alongside the original query, guiding the model to produce a factually grounded and current response [65]. This method directly counteracts the knowledge cutoff by ensuring the model does not rely solely on its static internal training data.
Real-Time Data Pipelines
For RAG systems to be effective, the underlying knowledge base must be continuously updated. Real-time data pipelines are infrastructure components that automate the flow of fresh information from source systems—such as scientific databases, IoT sensors in manufacturing, or newly published literature—into the vector stores or search indexes used by the RAG system [66] [67]. This continuous synchronization ensures that the context retrieved for the LLM is always aligned with the latest available data, which is critical for time-sensitive applications like monitoring chemical processes or tracking regulatory changes.
Direct Model Context Protocol (MCP) Integration
Emerging standards like the Model Context Protocol (MCP) provide a structured framework for supplying LLMs with real-time, semantically rich data directly from enterprise systems without the need for data replication [66]. This allows researchers to connect LLMs directly to live operational data sources, such as electronic lab notebooks or environmental monitoring systems, providing models with immediate access to the most current experimental results and process metrics.
Application in Chemical Life Cycle Assessment Research
The integration of real-time data is transforming LCA research methodologies. The following table summarizes the quantitative environmental impact of using a typical LLM compared to human labor for a text-based task, highlighting the potential efficiency gains [68].
Table 1: Environmental and Economic Impact of Generating a 500-Word Page of Content: LLM vs. Human Labor
| Metric | Llama-3-70B (LLM) | Human (U.S. Resident) | Human-to-LLM Ratio |
|---|---|---|---|
| Energy Consumption | 0.020 kWh | 0.85 kWh | 43 |
| Carbon Emissions | 15 grams CO₂ | 800 grams CO₂ | 53 |
| Water Consumption | 0.14 liters | 5.7 liters | 41 |
| Economic Cost | $0.08 | $12.1 | 151 |
Automated Data Retrieval from Scientific Literature
Manually compiling life cycle inventory data is a time-consuming process that requires extensive literature review. A framework leveraging a retrained LLM, termed "Sustain-LLaMA," has been developed to automate the retrieval of LCI and environmental impact data from scientific literature [22]. This system follows a structured, three-stage workflow to ensure accuracy and relevance.
Table 2: Performance Metrics of the Sustain-LLaMA Framework
| Component | Task | Performance Metric | Score |
|---|---|---|---|
| Classification Model | Identify relevant scientific documents | Accuracy | 0.850 (Methanol), 0.952 (Plastic Packaging) |
| Q&A Model with RAG | Extract LCI & environmental impact data | F1 Score | 0.823 (Methanol), 0.855 (Plastic Packaging) |
Diagram 1: Sustain-LLaMA Workflow for LCI Data Retrieval.
Entity Linking for Carbon Footprint Estimation
Another critical application involves automating the mapping of product components to LCA databases. A common challenge is that components in Bills of Materials (BOMs) often use internal supplier names or specification codes, requiring specialist knowledge to map to standardized LCA database entries. A multi-step LLM-based framework addresses this by enriching component information to enable accurate entity linking [69].
Experimental Protocol: Entity Linking for Carbon Footprint
- Datasheet Selection: For a given BOM entry (component name, supplier, material), search a pool of technical datasheets. Compute the cosine similarity between the embedding of the BOM entry and the embedding of each datasheet (filename + content). Select the datasheet with a cosine similarity ≥ 0.5 for further processing [69].
- LLM Querying: Construct a prompt containing the BOM entry information and the text from the matched datasheet (if available). Instruct a locally run LLM (e.g., Llama 3.1 8B) to generate a descriptive summary of the manufacturing process used to create the component [69].
- Semantic Similarity Matching: a. Preprocessing: Create a vector store (e.g., using FAISS) containing embeddings of all process names and descriptions from the target LCA database (e.g., ecoinvent) [69]. b. Matching: Generate an embedding of the LLM's process description. Query the vector store to find the top N LCA database entries with the highest cosine similarity to the LLM's description [69].
- Validation: The ranked list of potential matches is presented to an LCA expert for final validation and selection, streamlining the expert's workflow rather than replacing it [69].
Table 3: Performance Comparison of Entity Linking Methods (Hits@N)
| Method | Hits@5 | Hits@1 | Description |
|---|---|---|---|
| Human (Non-Expert) | 0.48 | 0.19 | Baseline human performance |
| Semantic Similarity Only | 0.05 | 0.00 | Using only BOM text, no LLM |
| LLM | 0.43 | 0.19 | Using LLM to describe the process |
| LLM + Datasheet | 0.48 | 0.24 | Using LLM with additional datasheet context |
Diagram 2: Entity Linking Workflow for LCA Database Matching.
The Scientist's Toolkit: Essential Research Reagents & Solutions
Table 4: Key Research Reagents and Computational Tools for Real-Time LCA
| Item Name | Function / Application | Example/Notes |
|---|---|---|
| Sustain-LLaMA Framework | Automated retrieval of LCI & environmental impact data from scientific literature. | A fine-tuned LLaMA-2-7B model, specialized for LCA tasks [22]. |
| RAG Pipeline | Overcoming LLM knowledge cutoffs by integrating external, real-time data at inference. | Can be built using frameworks like LangChain; requires a vector database [65]. |
| Vector Database (VDB) | Enables fast semantic search across unstructured text data by storing vector embeddings. | Examples: Pinecone, FAISS. Critical for efficient retrieval in RAG [65] [69]. |
| Real-Time Data Integration Platform | Creates continuous data pipelines from source systems (e.g., lab databases) to vector stores. | Platforms like Estuary Flow or CData Connect AI can sync data in real-time using CDC [66] [67]. |
| Entity Linking Toolchain | Automates the mapping of BOM components to entries in LCA databases using LLMs. | Utilizes LLMs (e.g., Llama 3.1 8B) and semantic similarity matching (e.g., with gte-large-en-v1.5 embeddings) [69]. |
| LCA Database | Provides authoritative life cycle inventory and environmental impact data. | ecoinvent is a widely used database in the presented research [69]. |
| Model Context Protocol (MCP) | A standard for providing LLMs with governed, real-time access to live data sources. | Allows direct querying of operational systems without data replication [66]. |
The knowledge cutoff inherent in static LLMs presents a significant barrier to their reliable application in chemical life cycle assessment and drug development. However, techniques like Retrieval-Augmented Generation (RAG), supported by real-time data pipelines and specialized frameworks like Sustain-LLaMA, provide a robust methodological solution. By systematically integrating these protocols, researchers can leverage the power of LLMs while ensuring their outputs are grounded in the most current and relevant scientific data, thereby enhancing the accuracy, efficiency, and reliability of environmental sustainability research.
Addressing Computational and Token Constraints in Complex LCA Modeling
Large language models (LLMs) are revolutionizing chemical research, offering new methodologies for understanding disease mechanisms and accelerating drug discovery [54]. However, their integration into life cycle assessment (LCA) for chemical research presents significant computational and token constraints. LCA, a standardized methodology for evaluating environmental impacts across a product's life cycle from raw material extraction to end-of-life disposal, involves complex data-intensive phases that strain computational resources when combined with LLMs [70] [71] [31]. This application note provides detailed protocols for overcoming these constraints, enabling researchers to leverage LLMs effectively within chemical LCA workflows while maintaining scientific rigor and computational feasibility.
The fusion of LLMs with LCA is particularly relevant for drug development professionals seeking to quantify the environmental footprint of pharmaceutical products and processes. LLMs can assist in clarifying disease mechanisms, identifying potential drug targets, and even automating chemistry experiments [54]. Yet, the computational demands of both LLMs and LCA modeling create bottlenecks that require strategic approaches to data management, model selection, and workflow optimization. The following sections outline specific solutions to these challenges, supported by experimental protocols and quantitative performance data.
Quantitative Analysis of ML Algorithms for LCA
Selecting appropriate machine learning (ML) algorithms is crucial for balancing computational efficiency and predictive accuracy in LCA studies. Evidence-based ranking of ML models helps researchers optimize resource allocation while maintaining reliable environmental impact assessments.
Table 1: Performance Ranking of Machine Learning Algorithms for LCA Applications [72]
| Machine Learning Model | Performance Score (0-1 scale) | Primary Strengths | Computational Demand |
|---|---|---|---|
| Support Vector Machine (SVM) | 0.6412 | Handles high-dimensional data effectively | Moderate |
| Extreme Gradient Boosting (XGB) | 0.5811 | High accuracy with structured data | Moderate to High |
| Artificial Neural Networks (ANN) | 0.5650 | Models complex non-linear relationships | High |
| Random Forest (RF) | 0.5353 | Robust to outliers and noise | Moderate |
| Decision Trees (DT) | 0.4776 | Simple and interpretable | Low |
| Linear Regression (LR) | 0.4633 | Fast and simple for linear relationships | Very Low |
| Adaptive Neuro-Fuzzy Inference System (ANFIS) | 0.4336 | Combines reasoning and learning | High |
| Gaussian Process Regression (GPR) | 0.2791 | Provides uncertainty estimates | Very High |
The performance scores indicate that SVM, XGB, and ANN models achieve the highest effectiveness for LCA predictions, making them particularly suitable for resource-intensive applications in chemical research [72]. However, researchers working under significant computational constraints might opt for Random Forest or Decision Trees, which offer reasonable performance with lower resource requirements. This trade-off between accuracy and computational demand is particularly relevant when integrating LLMs into the LCA workflow, as both technologies strain available resources.
Protocol for LLM Integration in LCA Phases
This protocol provides a systematic approach for incorporating LLMs into chemical LCA research while managing computational overhead and token limitations.
Phase 1: Goal and Scope Definition with LLM Assistance
Objective: Leverage LLMs for efficient literature synthesis and scope refinement while minimizing computational costs.
Materials and Reagents:
- LLM Access: API or local instance of a capable LLM (e.g., GPT, Gemini, or domain-specific models like Galactica)
- Reference Management Software: Zotero, Mendeley, or Citavi
- Text Processing Tools: Python NLTK library or R tidytext package
Procedure:
- Prompt Engineering for Scope Delineation:
- Input: "Identify key system boundaries and impact categories for LCA of [specific chemical process or drug compound]"
- Parameters: Set
max_tokens = 500to constrain output length and computational load - Apply temperature setting of 0.3 to reduce response variability while maintaining creativity
Functional Unit Definition:
- Utilize few-shot learning with 3-5 examples of well-defined functional units from similar chemical LCAs
- Implement iterative refinement: Analyze initial LLM output, then prompt with "Improve the functional unit definition considering [specific constraints]"
Boundary Selection Optimization:
- Process LLM outputs through a decision tree classifier to identify relevant life cycle stages
- Apply token compression techniques by replacing verbose text with standardized codes for common LCA concepts
Troubleshooting:
- For overly generic responses: Incorporate domain-specific context through chemical ontologies and controlled vocabularies
- For token limit errors: Implement text chunking strategies, processing life cycle stages sequentially rather than simultaneously
Phase 2: Life Cycle Inventory (LCI) Analysis with Computational Constraints
Objective: Efficiently compile comprehensive inventory data while managing data processing loads.
Materials and Reagents:
- LCA Databases: Ecoinvent, GREET, or specific chemical databases like PubChem LCA
- Data Processing Tools: Python Pandas library, OpenLCA API
- LLM Integration: Fine-tuned LLM for chemical data extraction (e.g., model trained on SMILES notations)
Procedure:
- Sparse Data Imputation:
- Apply XGBoost algorithm (performance score: 0.5811) for missing data estimation using the protocol:
- Train on complete LCI datasets with 10-fold cross-validation to prevent overfitting
- Implement feature importance analysis to prioritize high-impact data collection
- Use Synthetic Minority Over-sampling Technique (SMOTE) for balancing sparse categorical data
LLM-Assisted Data Extraction:
- Configure LLM with constrained context window (e.g., 2000 tokens) for processing scientific literature
- Implement a hybrid approach: Use LLM for initial data identification, then traditional methods for verification
- Apply named entity recognition (NER) fine-tuned on chemical terminology to improve extraction accuracy
Uncertainty Quantification:
- Implement Gaussian Process Regression (performance score: 0.2791) selectively for critical inventory items only
- Use Random Forest (performance score: 0.5353) for less critical items to conserve computational resources
Figure 1: Computational-aware workflow for Life Cycle Inventory analysis with optimized resource allocation.
Phase 3: Life Cycle Impact Assessment (LCIA) with Resource Optimization
Objective: Conduct comprehensive impact assessment while managing computational intensity.
Materials and Reagents:
- LCIA Methodologies: ReCiPe, TRACI, or CML baseline methods
- Computational Tools: Brightway2, SimaPro, or custom Python/R scripts
- LLM Components: Encoder-decoder models for impact category selection
Procedure:
- Surrogate Modeling:
- Train SVM models (performance score: 0.6412) as surrogates for computationally intensive LCIA calculations
- Implement active learning: Select most informative data points for manual calculation to maximize knowledge gain per computation
- Create model ensembles: Combine predictions from SVM and ANN models for uncertainty reduction
Hybrid LCIA Modeling:
- Develop a tiered approach: Level 1 (screening): Simplified calculations for all impact categories; Level 2 (detailed): Full assessment for significant categories only
- Apply transfer learning: Pre-train models on similar chemical LCAs before fine-tuning on specific assessment
- Implement early stopping: Halt iterative calculations when convergence criteria are met
Dynamic Characterization Factors:
- Utilize LLMs with tool augmentation (e.g., Python code execution) to calculate context-specific characterization factors
- Cache frequently used factors to avoid redundant computations
- Implement memoization for recursive calculations in temporal impact assessments
Objective: Derive meaningful insights from LCA results while respecting computational boundaries.
Materials and Reagents:
- Statistical Packages: R stats, Python scikit-learn, or specialized LCA interpretation tools
- Visualization Libraries: Matplotlib, Plotly, or Tableau
- LLM Analytics: Fine-tuned models for pattern recognition in LCA results
Procedure:
- Hotspot Identification:
- Implement Random Forest (performance score: 0.5353) for feature importance analysis to identify significant impact drivers
- Use LLMs with constrained context windows for multi-criteria decision analysis
- Apply sensitivity analysis selectively based on preliminary screening results
Uncertainty Propagation:
- Implement Monte Carlo simulations with optimized sample sizes (determined through power analysis)
- Use quasi-Monte Carlo methods with low-discrepancy sequences for faster convergence
- Apply variance-based sensitivity analysis (Sobol indices) for key parameters only
Stakeholder Communication:
- Utilize LLMs for generating plain-language summaries with technical depth controls
- Implement prompt chaining: Break complex interpretation tasks into sequential, manageable steps
- Apply output compression: Use dense summarization techniques to maintain information density within token limits
Advanced Integration Framework
The AI integration architecture for LCA studies emphasizes retaining human insight and control while leveraging computational efficiencies [31]. For chemical research applications, this translates to a hybrid approach where LLMs and traditional ML algorithms operate within a structured framework that prioritizes critical computations and allocates resources accordingly.
Table 2: Research Reagent Solutions for Computational LCA Modeling
| Reagent/Tool | Function | Implementation Consideration |
|---|---|---|
| SVM (Support Vector Machine) | High-accuracy prediction for LCIA | Use for priority impact categories only due to moderate computational demand |
| XGBoost (Extreme Gradient Boosting) | Data imputation and pattern recognition | Effective for structured LCI data with missing values |
| Transformer Architectures | Natural language processing for goal and scope | Deploy with constrained context windows (≤2048 tokens) |
| Fine-tuned Domain LLMs (e.g., Galactica) | Chemical-specific data extraction | Requires specialized training but reduces hallucination |
| Random Forest | Feature importance and screening | Low computational cost suitable for preliminary analyses |
| Hybrid LM/LLM Methods | Combine strengths of multiple approaches | Use reinforcement learning to steer outputs toward desired properties |
Figure 2: AI integration framework for LCA showing the interaction between human expertise, active/passive LLM environments, and ML ensembles.
The distinction between "active" and "passive" LLM environments is crucial for managing computational constraints [60]. In passive environments, LLMs answer questions based solely on training data, while active environments enable interaction with databases and instruments for real-time information gathering. For chemical LCA, a balanced approach employs passive environments for knowledge-intensive tasks (minimizing computation) and active environments only for critical decision points requiring current data.
Addressing computational and token constraints in complex LCA modeling requires a strategic approach to resource allocation, algorithm selection, and workflow design. By implementing the protocols outlined in this application note, chemical researchers and drug development professionals can effectively leverage LLMs and ML algorithms within their LCA workflows while maintaining computational feasibility. The performance rankings of ML algorithms provide evidence-based guidance for model selection, while the structured protocols offer practical solutions for each LCA phase. As LLM capabilities continue to evolve, the framework presented here allows for integration of more sophisticated models while respecting the fundamental constraints inherent in computational sustainability assessment.
The integration of large language models (LLMs) and other artificial intelligence (AI) technologies into chemical life cycle assessment (LCA) research presents transformative potential for accelerating drug development and sustainability innovations. However, these systems also introduce significant ethical risks, including algorithmic bias, environmental impacts, and accountability gaps that require rigorous oversight frameworks. For researchers, scientists, and drug development professionals, establishing robust ethical protocols is not merely a compliance exercise but a fundamental requirement for scientific integrity and responsible innovation. The Institute of Electrical and Electronics Engineers (IEEE) emphasizes that algorithmic systems influencing critical decisions require comprehensive bias considerations throughout their lifecycle [73]. Similarly, educational institutions have adopted ethical frameworks based on the Belmont Report's foundational principles of respect for persons, beneficence, and justice [74]. This document provides detailed application notes and experimental protocols for implementing ethical oversight and bias mitigation specifically within LLM-driven chemical LCA research, ensuring that technological advancements align with scientific values and societal expectations.
Foundational Ethical Principles for AI in Research
The ethical deployment of AI in chemical LCA research should be guided by established principles that have been adapted to the specific context of scientific investigation and drug development. These principles provide the philosophical foundation for the technical protocols that follow.
Beneficence: AI systems should actively promote the well-being of research communities, patients, and the environment by enhancing research outcomes while carefully mitigating risks such as privacy concerns, biases, and inaccuracies [74]. In practice, this means prioritizing AI applications that align with institutional and scientific values over those driven purely by commercial interests.
Justice: AI integration must emphasize the inclusion of marginalized voices, images, and stories that have traditionally been omitted from scientific datasets, which has led to disproportionate information from majority groups [74]. This principle requires ensuring equitable access to AI tools and resources across different socioeconomic backgrounds and institutions.
Respect for Autonomy: This principle upholds the rights of researchers, subjects, and stakeholders to make informed decisions regarding AI interactions, including understanding how AI systems influence research outcomes and conclusions [74].
Transparency and Explainability: Research must provide clear, understandable information about how AI systems operate, particularly when these systems influence scientific conclusions or drug development pathways [74] [75]. This is crucial for peer review and validation of AI-assisted research.
Accountability and Responsibility: Institutions, developers, and principal investigators must be held accountable for the AI systems they deploy, with clear assignment of responsibility for ethical outcomes [74] [75].
Privacy and Data Protection: Safeguarding personal and proprietary research information against unauthorized access and breaches is paramount, especially when AI systems handle sensitive chemical data or patient information [74] [75].
Nondiscrimination and Fairness: Preventing biases in AI algorithms that could lead to discriminatory outcomes in research applications or the resulting products and technologies [74].
These principles are profoundly interconnected and should be considered holistically rather than in isolation when implementing AI systems in chemical LCA research [74].
Algorithmic Bias Mitigation Framework
Bias Risk Assessment and Mitigation Protocol
The following protocol provides a systematic approach to identifying, assessing, and mitigating algorithmic bias throughout the AI lifecycle in chemical LCA research, based on the IEEE 7003-2024 standard [73].
Objective: To establish a reproducible methodology for bias detection and mitigation in LLMs applied to chemical LCA research. Materials: Representative chemical datasets, bias assessment toolkit (e.g., AI Fairness 360, Fairlearn), documentation templates, cross-functional review team. Duration: Ongoing throughout the AI system lifecycle.
| Protocol Step | Key Activities | Documentation Output | Quality Controls |
|---|---|---|---|
| 1. Bias Profile Creation | - Document system purpose, context of use- Identify protected groups & attributes- Define fairness criteria & metrics | Bias Profile Document | Review by ethics committee & domain experts |
| 2. Stakeholder Mapping | - Identify impacted researcher communities- Engage diverse scientific perspectives- Map decision influence pathways | Stakeholder Analysis Matrix | Inclusion of underrepresented research domains |
| 3. Data Representation Audit | - Assess dataset coverage of chemical domains- Analyze representation of rare compounds- Evaluate data collection methodologies | Data Quality Report | Statistical analysis of representation gaps |
| 4. Pre-deployment Bias Testing | - Implement counterfactual fairness tests- Conduct cross-domain validation- Perform adversarial testing | Bias Assessment Report | Benchmarking against established baselines |
| 5. Continuous Monitoring | - Monitor for data/concept drift- Track performance across subpopulations- Establish retraining triggers | Monitoring Dashboard & Alerts | Regular audit schedules & review cycles |
Bias Mitigation Workflow Visualization
Bias Mitigation Workflow: This diagram illustrates the iterative process for identifying and addressing algorithmic bias in AI systems used for chemical LCA research.
Environmental Impact Assessment Framework
Quantitative Environmental Impact of AI Models
The environmental footprint of LLMs represents a significant ethical consideration for research institutions committed to sustainability. The table below summarizes key environmental impact metrics for AI model development and deployment based on recent lifecycle assessments [76] [77].
| Model / Activity | GHG Emissions | Water Consumption | Resource Depletion | Measurement Context |
|---|---|---|---|---|
| GPT-3 Training | 552 tCO₂e | Not specified | Not specified | Single training cycle [76] |
| GPT-4 Training | 21,660 tCO₂e | Not specified | Not specified | Estimated full training [76] |
| Mistral Large 2 Training | 20.4 ktCO₂e | 281,000 m³ | 660 kg Sb eq | 18-month usage period [77] |
| GPT-4o Inference | 0.3 Wh/query | Not specified | Not specified | Per query estimate [76] |
| Mistral Inference | 1.14 gCO₂e | 45 mL | 0.16 mg Sb eq | Per 400-token response [77] |
| GPU Manufacturing | 19.2M tCO₂e (2030 projection) | Not specified | Not specified | Annual industry projection [76] |
Sustainable AI Implementation Protocol
Objective: To minimize the environmental footprint of AI systems used in chemical LCA research while maintaining scientific rigor. Materials: Energy consumption monitoring tools, cloud provider efficiency metrics, model optimization libraries, computing resource allocation system. Duration: Continuous throughout research project lifecycle.
| Protocol Step | Implementation Guidelines | Expected Impact | Validation Metrics |
|---|---|---|---|
| 1. Model Selection | - Choose smallest viable model- Use task-specific models- Consider sparse architectures | 40-70% energy reduction | Parameters count; FLOPs/operation |
| 2. Hardware Optimization | - Utilize energy-efficient processors- Implement advanced cooling | 15-52% resource reduction | PUE; WUE; Carbon intensity |
| 3. Training Efficiency | - Apply early stopping- Use mixed precision- Implement progressive training | Up to 75% training energy savings | Training time; Energy consumption |
| 4. Inference Management | - Batch processing- Query optimization- Cache frequent computations | 5-10x efficiency vs. training | Watts/query; Throughput |
| 5. Lifecycle Assessment | - Track full lifecycle impacts- Include upstream manufacturing- Regular efficiency audits | Comprehensive impact accounting | GHG; Water; Resource depletion |
AI Environmental Impact Assessment Workflow
Environmental Assessment Workflow: This diagram shows the systematic process for evaluating and minimizing the environmental impacts of AI systems in research contexts.
Research Reagent Solutions: Ethical AI Toolkit
The following table details essential tools, frameworks, and resources that constitute the "research reagent solutions" for implementing ethical AI oversight in chemical LCA research.
| Tool Category | Specific Solutions | Function | Application Context |
|---|---|---|---|
| Bias Assessment | AI Fairness 360 (AIF360) | Comprehensive metrics & algorithms for bias detection | Pre-deployment model validation [73] |
| Fairlearn | Visualization & mitigation of unfairness | Model performance across subgroups [73] | |
| Transparency Tools | SHAP (SHapley Additive exPlanations) | Model interpretability & feature importance | Understanding model predictions [75] |
| LIME (Local Interpretable Model-agnostic Explanations) | Local model explanations | Individual prediction rationale [75] | |
| Environmental Monitoring | Zeus Optimization Framework | GPU energy consumption optimization | Training efficiency improvements [76] |
| Carbone 4 LCA Methodology | Standardized environmental impact assessment | Comprehensive footprint calculation [77] | |
| Governance Frameworks | IEEE 7003-2024 Standard | Algorithmic bias considerations | End-to-end bias mitigation [73] |
| EU AI Act Compliance Tools | Regulatory requirement implementation | Legal compliance management [31] |
Implementation Checklist for Research Teams
The following checklist provides a practical guide for research teams implementing ethical AI oversight in chemical LCA projects:
Pre-Project Planning
- Establish cross-functional ethics review team including domain experts, data scientists, and environmental specialists
- Define explicit fairness criteria and environmental impact budgets for the project
- Conduct preliminary bias and sustainability risk assessment
- Select appropriate model architectures balancing performance with efficiency requirements
- Document decision rationale for model selection and intended use cases
Development Phase
- Audit training data for representation across chemical domains and compound classes
- Implement energy-efficient training protocols with continuous monitoring
- Conduct iterative bias testing using multiple metrics and validation sets
- Document all design choices, data sources, and optimization techniques
- Perform third-party validation of bias claims and efficiency metrics
Deployment and Monitoring
- Establish continuous monitoring for model performance across chemical subdomains
- Implement alert systems for concept drift or performance degradation
- Track computational efficiency and environmental impact metrics
- Maintain version control for model updates and retraining cycles
- Schedule regular ethics reviews and impact assessments
By adhering to these application notes and protocols, research teams can harness the power of LLMs and AI systems for chemical life cycle assessment while maintaining rigorous ethical standards, minimizing environmental impacts, and ensuring the responsible advancement of drug development and sustainability science.
Application Note: Quantifying the Environmental Footprint of LLMs
The integration of Large Language Models (LLMs) into research pipelines, particularly in chemical life cycle assessment (LCA), necessitates a thorough understanding of their resource consumption. The environmental impact of LLMs is driven by substantial computational requirements during both training and inference phases, leading to significant energy use, carbon emissions, and water consumption [16] [78].
Energy Consumption and Carbon Emissions: The operational energy required for inference in LLMs is a primary contributor to their carbon footprint. For instance, generating a 500-word page of content using a typical LLM like Llama-3-70B consumes approximately 0.020 kWh of energy and results in about 15 grams of CO₂ emissions [68]. In contrast, a single ChatGPT query is estimated to consume about five times more electricity than a simple web search [16]. Training larger models is even more resource-intensive; training GPT-3 consumed an estimated 1,287 MWh of electricity, generating approximately 552 tons of carbon dioxide [79] [16] [80].
Water Consumption: Data centers rely on water for cooling, contributing significantly to the water footprint of AI. It is estimated that for every kilowatt-hour of energy a data center consumes, it needs two liters of water for cooling [78]. ChatGPT uses around 500 milliliters of water per prompt, and global AI water demand could reach between 4.2 and 6.6 billion cubic meters by 2027 [78].
Table 1: Comparative Environmental Impact of LLM Inference vs. Human Labor for a 500-word Task
| Metric | Llama-3-70B (LLM) | Gemma-2B-it (Lightweight LLM) | Human Labor (U.S. Resident) |
|---|---|---|---|
| Energy Consumption (kWh) | 0.020 | 0.00024 | 0.85 |
| Carbon Emissions (g CO₂) | 15 | 0.18 | 800 |
| Water Consumption (Liters) | 0.14 | 0.0017 | 5.7 |
| Economic Cost (USD) | $0.08 | $0.01 | $12.1 |
| Data sourced from a comparative life cycle assessment [68] |
Model Size and Infrastructure: The environmental impact is correlated with model size, often measured by the number of parameters. Larger models demand more computational power and energy [79] [80] [78]. The infrastructure efficiency, measured by Power Usage Effectiveness (PUE), also plays a critical role. Google's data centers, for example, have a PUE of 1.12, meaning only 12% of energy is used for overhead, whereas less efficient data centers can have a PUE of 2.0 or higher, drastically increasing waste [80].
Protocol for Efficient LLM Deployment in Chemical LCA Research
This protocol provides a framework for deploying LLMs in chemical Life Cycle Assessment (LCA) research with a focus on optimizing the balance between performance, cost, and environmental sustainability. The workflow involves model selection, optimization, and impact measurement.
Step 1: Task Complexity Assessment and Model Selection
Objective: To select the most efficient LLM that is fit-for-purpose for the specific LCA task.
Categorize Task Complexity:
- Low Complexity: Simple text summarization of known data, template-based reporting.
- Medium Complexity: Answering complex queries, multi-step text generation.
- High Complexity/Domain-Specific: Retrieving and synthesizing Life Cycle Inventory (LCI) data from scientific literature, complex reasoning on environmental impact factors [22].
Apply Model Selection Framework:
- For Low Complexity tasks, select a lightweight model (e.g., Gemma-2B-it with 2 billion parameters) to minimize energy consumption and cost [68] [81].
- For Medium Complexity tasks, a typical general model (e.g., Llama-3-70B with 70 billion parameters) may be necessary, but must be coupled with optimization techniques [68].
- For High Complexity/Domain-Specific tasks (e.g., LCI data retrieval), consider using a specialized or retrained model. The framework for "Sustain-LLaMA" demonstrates how a base model (LLaMA-2-7B) can be retrained on scientific literature to accurately extract LCI and environmental impact data, improving efficiency for a narrow domain [22].
Step 2: Application of Model Optimization Techniques
Objective: To reduce the computational load, memory footprint, and inference latency of the selected model without significantly compromising performance for the LCA task.
Quantization:
- Procedure: Convert the model's parameters from 32-bit or 16-bit floating-point precision (FP32/FP16) to lower precision (e.g., 8-bit integers - INT8). This can be done post-training using frameworks like TensorRT [81].
- Rationale: Reduces the model's memory footprint and computational requirements, leading to faster inference and lower energy consumption [81].
Knowledge Distillation:
- Procedure: Train a smaller, more efficient "student" model to mimic the behavior of a larger, more powerful "teacher" model. The student model learns from the teacher's output probabilities [81].
- Rationale: Creates a smaller model that retains much of the teacher's performance but is far more efficient to run, ideal for deploying LCA tools in resource-constrained environments [78] [81].
Architectural Optimizations:
- KV Cache Optimization: Compress the Key-Value (KV) cache, which stores past activations, to reduce memory bottlenecks during the generation of long texts [81].
- Sparsity and Pruning: Permanently remove redundant parameters or attention layers from the model that contribute minimally to its output [78] [81].
Step 3: Deployment, Inference, and Impact Measurement
Objective: To run the optimized model and quantitatively track its environmental impact.
Deployment and Scheduling:
- Use a high-throughput inference server like vLLM, which optimizes memory management and GPU utilization, for production-level workloads [79].
- Schedule non-urgent, batch inference tasks (e.g., processing large literature datasets) for periods when the local power grid has a lower carbon intensity (e.g., during high renewable energy availability) [82].
Impact Measurement and Reporting:
- Procedure: Integrate a carbon tracking tool like CodeCarbon into the inference pipeline. This tool reads low-level hardware sensors to estimate power consumption per component [79] [82].
- Data to Record:
- Token Usage: Track the number of tokens processed per API call or session [82].
- Operational Energy: Total energy consumed by CPU and GPU during the inference task.
- Carbon Equivalents (CO₂eq): Calculate emissions based on energy consumed and the local grid's carbon intensity. CodeCarbon can automate this [79].
- Model and Infrastructure Details: Record model type, version, cloud region, and hardware used [82].
The Scientist's Toolkit: Reagents and Materials for LLM Efficiency Research
Table 2: Essential "Research Reagents" for LLM Efficiency and LCA Experiments
| Item | Function / Explanation |
|---|---|
| vLLM | A high-throughput, production-ready LLM inference serving backend. It optimizes memory management via the PagedAttention algorithm, increasing throughput and reducing latency, which directly improves energy efficiency [79]. |
| CodeCarbon | A software tool that estimates power consumption and carbon emissions by reading hardware sensors (e.g., via NVIDIA-smi). It is essential for quantifying the environmental impact of LLM experiments [79] [82]. |
| TensorRT | An NVIDIA platform for high-performance deep learning inference. It provides advanced optimization techniques, including state-of-the-art quantization and specialized plugins for attention mechanisms, to deploy models with low latency and high throughput [81]. |
| Sustain-LLaMA | An example of a domain-specific LLM, retrained from LLaMA-2-7B, designed for retrieving LCI and environmental impact data from scientific literature. It demonstrates the utility of specialized models for sustainable chemistry research [22]. |
| H100/A100 GPUs | High-performance hardware accelerators from NVIDIA. Their efficiency (performance per watt) is a critical variable in the total energy consumption of training and running LLMs [80] [68]. |
Protocol for Experimental Validation of LLM Efficiency
This protocol outlines a benchmark experiment to compare the performance and efficiency of different LLMs and optimization techniques, simulating a realistic LCA data retrieval task.
Step 1: Experimental Setup and Parameter Definition
Objective: To establish a controlled benchmarking environment for comparing LLM efficiency.
Define Model and Optimization Variants:
- Select a minimum of three model variants: a base model (e.g., LLaMA-2-7B), a distilled version of it, and a quantized version of the base model.
- Use the same base model architecture to ensure a fair comparison of optimization techniques [79].
Prepare Query Dataset:
- Use a standardized dataset like HellaSwag, which contains sentence completion tasks, to simulate a realistic workload [79].
- Alternatively, for LCA-specific benchmarking, create a custom dataset of prompts designed to query LCI data or environmental impacts.
Set System Configuration:
Step 2: Benchmark Execution and Data Collection
Objective: To execute the benchmark and collect quantitative data on performance and environmental impact.
Instrumentation and Warm-up:
Run Main Benchmark:
- Send the entire prepared dataset of test requests to the API endpoint. The benchmark should be configured to send all requests simultaneously (no rate limiting) to test peak load performance [79].
- Ensure the CodeCarbon tracker runs continuously until all requests are processed and returned.
Data Collection Points:
- Performance Metrics: Log throughput (tokens/second) and latency (time to first token, time per output token) from the inference server.
- Energy Metrics: Record the total energy consumed (in kWh) from CodeCarbon.
- Carbon Metrics: Record the estimated CO₂eq emissions from CodeCarbon.
- Accuracy/Quality Metrics: If applicable, evaluate the output quality of the models (e.g., using a scoring metric for task accuracy).
Step 3: Data Analysis and Reporting
Objective: To synthesize the collected data into actionable insights for selecting efficient models.
Calculate Composite Efficiency Scores:
- Create a normalized score that balances performance (e.g., throughput) and environmental cost (e.g., energy per token). For example:
Efficiency Score = (Throughput in tok/s) / (Energy in kWh). - A higher score indicates a more efficient model.
- Create a normalized score that balances performance (e.g., throughput) and environmental cost (e.g., energy per token). For example:
Report Findings:
- Present results in a comparative table.
- Conclusion: The analysis should clearly indicate which model and optimization technique provides the best trade-off for the target application, enabling researchers to make an informed, sustainable choice.
Benchmarking Performance: Validating LLM Outputs Against Expert Ground Truth
Establishing Expert-Grounded Benchmarks for LLMs in LCA
The integration of large language models (LLMs) into chemical life cycle assessment (LCA) research presents a paradigm shift, offering potential breakthroughs in overcoming traditional methodological bottlenecks. However, the absence of standardized, expert-validated benchmarks poses a significant risk to the reliability and adoption of these AI-driven tools. Demonstrating this concern, a recent expert-grounded evaluation found that 37% of LLM-generated responses contained inaccurate or misleading information, with some models producing hallucinated citations at rates up to 40% [41]. Within chemical LCA, where precise data and validated methodologies are paramount, such deficiencies can directly compromise the quality of carbon footprint accounting and environmental impact decisions [83] [30]. This document establishes detailed application notes and protocols for creating expert-grounded benchmarks, providing researchers and drug development professionals with a framework to quantitatively evaluate and responsibly deploy LLMs in chemical LCA workflows.
Quantitative Performance Landscape of General-Purpose LLMs in LCA
Initial benchmarking efforts reveal a nuanced performance landscape where no single model dominates across all criteria and task types. The following table synthesizes key quantitative findings from expert evaluations of eleven commercial and open-source LLMs across 22 LCA-related tasks, grounded in 168 expert reviews [41].
Table 1: Expert Evaluation of General-Purpose LLMs on LCA Tasks
| Evaluation Criterion | Performance Summary | Key Quantitative Findings | Implications for Chemical LCA |
|---|---|---|---|
| Scientific Accuracy | Mixed, significant risk | 37% of responses contained inaccurate/misleading information [41] | High risk for chemical impact factor calculation and carbon footprint reporting |
| Explanation Quality | Generally "average" to "good" | Quality rated favorably even for some smaller models [41] | Useful for explaining complex chemical impact pathways to non-experts |
| Hallucination Rate | Highly variable, critical weakness | Up to 40% hallucinated citation rate for some models [41] | Particularly dangerous for regulatory compliance and scientific reporting |
| Format Adherence | Generally strong | High rates of instruction-following capability [41] | Beneficial for standardized reporting templates in chemical LCA |
| Open vs. Closed Model Performance | No clear distinction | Open-weight models competed with or outperformed closed models on accuracy and explanation [41] | Promising for transparent, customizable chemical LCA implementations |
Specialized implementations demonstrate markedly improved performance. For instance, a Retrieval-Augmented Generation (RAG)-based system specifically designed for LCA achieved a BERTScore of 0.85 on domain-specific question-answering, while Text2SQL augmentation for life cycle inventory (LCI) database retrieval reached an execution accuracy of 0.97 [83]. These results highlight the limitations of general-purpose models and the necessity of domain adaptation, particularly for technical chemical LCA tasks involving database operations and specialized terminology.
Protocol for Establishing Expert-Grounded Benchmarks
Stage 1: Benchmark Design and Task Selection
Objective: Define a comprehensive set of tasks representing the core workflow of chemical LCA. Materials & Reagents:
- Domain Expertise: Panel of LCA practitioners and chemical domain specialists.
- Task Taxonomy: Framework categorizing LCA phases (Goal & Scope, Inventory Analysis, Impact Assessment, Interpretation).
- Document Corpus: Authoritative chemical LCA literature, regulatory guidelines, and standardized methodologies.
Procedure:
- Task Identification: Map LCA workflow to specific, prompt-able tasks. For chemical LCA, essential tasks include:
- Abbreviation/Definition Recognition: Expanding chemical process acronyms (e.g., "Expand PCF") and defining specialized terms (e.g., "Define characterization factor for TRACI") [84].
- Life Cycle Inventory (LCI) Database Querying: Natural language queries for chemical emission factors and energy consumption data (e.g., "Retrieve cradle-to-gate emission factors for acetylsalicylic acid synthesis") [83].
- Impact Assessment Interpretation: Explaining the environmental significance of calculated impacts for specific chemicals (e.g., "Interpret a global warming potential of 5.2 kg CO₂eq/kg for active pharmaceutical ingredient X") [41] [85].
- Report Generation: Automating sections of carbon footprint reports following standardized templates (e.g., "Generate the methodology section for an LCA report on solvent selection in drug formulation") [83].
Prompt Formulation: Develop standardized input templates for each task to ensure consistency, for example: "Define the following term: {chemical LCA term}" [84].
Ground Truth Establishment: For each task, establish a validated reference answer or scoring rubric through consensus among domain experts. This is critical given the lack of universal ground truth in many LCA methodological choices [41].
Stage 2: Model Evaluation and Expert Review
Objective: Generate and systematically evaluate LLM responses using a hybrid of automated metrics and human expert judgment. Materials & Reagents:
- LLM Panel: Diverse set of general-purpose and potentially fine-tuned models.
- Evaluation Platform: Structured platform for expert review (e.g., Zooniverse) [41].
- Rating Rubric: Standardized scorecard for expert assessors.
Procedure:
- Response Generation: Execute all formulated prompts against the selected LLM panel under controlled conditions (e.g., constant temperature parameters, standardized system prompts).
Multi-Dimensional Expert Rating: Engage a panel of experienced LCA practitioners to review responses against the following criteria, each rated on a Likert scale (e.g., 1-5) [41]:
- Scientific Accuracy: Factual correctness of the information provided.
- Explanation Quality: Clarity, coherence, and educational value of the reasoning.
- Robustness: Consistency across slightly varied prompt phrasings.
- Verifiability: Presence and accuracy of supporting citations or data sources.
- Adherence to Instructions: Precision in following output format requirements.
Automated Metric Calculation: Supplement expert review with task-specific automated metrics [83] [84]:
- Accuracy: For closed-ended tasks like abbreviation recognition [84].
- BERTScore: For semantic similarity in definitional and open-ended tasks [83] [84].
- F1 Score: For Named Entity Recognition (NER) tasks identifying chemicals, processes, and impact categories [84].
- FActScore: For factual accuracy in question-answering and report generation [84].
- Execution Accuracy (EX): For evaluating the functional correctness of generated code or database queries (e.g., Text2SQL) [83].
Stage 3: Analysis and Benchmark Reporting
Objective: Synthesize results into a comprehensive benchmark report that highlights model strengths, weaknesses, and potential risks. Procedure:
- Data Aggregation: Calculate average scores and standard deviations for each model, task, and evaluation criterion.
- Hallucination Quantification: Specifically calculate the rate of unverifiable or fabricated citations and data points [41].
- Gap Analysis: Identify tasks or domains (e.g., social LCA, advanced impact assessment methods) where model performance is consistently weak.
- Recommendation Formulation: Provide guidance on model selection for specific chemical LCA use cases, highlighting the necessity of expert oversight and grounding techniques like RAG.
Workflow Visualization for Benchmark Establishment
The following diagram illustrates the end-to-end workflow for establishing expert-grounded benchmarks, integrating the stages and protocols detailed above.
Diagram 1: Expert-Grounded Benchmark Establishment Workflow.
Implementation Toolkit for Specialized LLM Applications in Chemical LCA
Directly using general-purpose LLMs is fraught with risk. The following table details key "research reagent" solutions and techniques essential for building reliable, domain-specific LLM applications for chemical LCA.
Table 2: Essential Toolkit for Implementing Domain-Specific LLMs in Chemical LCA
| Tool / Technique | Category | Function in Chemical LCA | Reported Performance |
|---|---|---|---|
| Retrieval-Augmented Generation (RAG) [83] | External Augmentation | Grounds LLM responses in a vetted corpus of LCA literature, chemical databases, and regulatory documents to reduce hallucinations. | BERTScore of 0.85 on LCA QA [83] |
| Text2SQL with CoT/CoC [83] | Prompt Engineering / External Tool Use | Enables natural language querying of complex Life Cycle Inventory (LCI) databases, automating data retrieval. | Execution Accuracy of 0.97 [83] |
| Code Interpreter Agent [83] | External Tool Use | Automates data analysis, impact calculation, and the generation of charts and tables for carbon footprint reports. | Top performance in 4/5 report quality dimensions [83] |
| Multi-round Correction Process [86] | Evaluation & Iteration | Iteratively fixes erroneous AI-generated code (e.g., for calculation models) based on test case failures, mimicking debugging. | Enables functional correctness for environmental impact comparison [86] |
| Expert-in-the-Loop Adjudication [41] | Human Oversight | Provides final validation of LLM outputs (e.g., emission factor recommendations, critical interpretations) where accuracy is paramount. | Mitigates risks identified in 37% of inaccurate model responses [41] |
The integration of these components into a cohesive system is visualized below, depicting the information flow that ensures accuracy and reliability.
Diagram 2: Specialized LLM System Architecture for Chemical LCA.
The establishment of expert-grounded benchmarks is not an academic exercise but a fundamental prerequisite for the credible integration of LLMs into chemical LCA research. The protocols and application notes detailed herein provide a actionable roadmap for the community to develop such standards. The quantitative evidence clearly indicates that while general-purpose LLMs carry significant risks of inaccuracy and hallucination, specialized implementations leveraging RAG, tool augmentation, and expert oversight can dramatically enhance reliability and utility [41] [83]. For researchers and professionals in drug development, adopting this rigorous benchmarking mindset is critical to harnessing the power of AI—such as rapid chemical impact prediction [30] and automated report generation—without compromising the scientific integrity that underpins sustainable development and regulatory compliance. Future work must focus on creating larger, more diverse benchmarks and standardizing the evaluation of LLMs adapted specifically for the nuanced, data-intensive domain of chemical life cycle assessment.
For researchers in chemical life cycle assessment and drug development, the integration of Large Language Models (LLMs) offers a powerful tool for accelerating literature reviews, data extraction, and hypothesis generation. However, the propensity of these models to generate plausible but factually incorrect information—a phenomenon known as "hallucination"—poses a significant risk to scientific integrity. This analysis provides a structured, evidence-based framework for evaluating the accuracy and hallucination rates of leading LLMs, enabling professionals to select and deploy these tools with appropriate safeguards within critical research workflows.
Benchmarking studies conducted throughout 2025 provide clear metrics on the factual reliability of various LLMs. The following tables summarize key performance indicators from recent large-scale evaluations.
Table 1: Overall Hallucination and Accuracy Rates for Leading LLMs (2025 Data)
| Model | Hallucination Rate (%) | Factual Consistency Rate (%) | Data Source |
|---|---|---|---|
| Google Gemini-2.5-Flash-Lite | 3.3 | 96.7 | Vectara Leaderboard [87] |
| Microsoft Phi-4 | 3.7 | 96.3 | Vectara Leaderboard [87] |
| Meta Llama-3.3-70B-Instruct-Turbo | 4.1 | 95.9 | Vectara Leaderboard [87] |
| OpenAI GPT-5 High | 1.4 | 98.6 | Vectara Leaderboard [87] |
| OpenAI o3 Mini High Reasoning | 0.8 | 99.2 | Vectara Leaderboard [88] |
| Anthropic Claude Opus 4 | 4.8 | 95.2 | Vectara Leaderboard [88] |
Table 2: OpenAI Model Performance Comparison on MMLU Benchmark
| Model | MMLU Accuracy (%) | Context |
|---|---|---|
| GPT-5 | 91.4 | 15,908 questions across 57 subjects [88] |
| GPT-4.1 | 90.2 | Massive Multitask Language Understanding benchmark [88] |
| Human Experts | 89.8 | Average performance for comparison [88] |
| GPT-4o | 88.7 | Massive Multitask Language Understanding benchmark [88] |
A critical insight from recent research is that a higher price does not automatically lead to improved accuracy or reliability. Some low-cost models demonstrate performance levels comparable to or even exceeding those of more expensive alternatives, indicating that factors such as model architecture, dataset quality, and training techniques have a greater impact on reducing hallucination rates than cost alone [89].
Experimental Protocols for LLM Evaluation
Standardized Hallucination Benchmarking
The Vectara Hallucination Leaderboard employs a rigorous, standardized methodology to evaluate model propensity for factual fabrication [87] [90].
3.1.1 Protocol Summary
- Objective: Quantify the rate at which LLMs introduce unsupported factual claims during a document summarization task.
- Dataset: Over 7,700 unique articles spanning technology, science, medicine, law, finance, and business, with a mix of low and high-complexity texts and lengths up to 32K tokens [90].
- Task Prompt: "You are a concise, factual summarizer. Read the following text and summarize it in a few sentences. Do not add any information outside of the source text. Do not add any opinions or interpretations. Your summary should be based solely on the provided text." [90]
- Evaluation Metric: A commercial Hallucination Detection Model (HHEM) scores each summary between 0-1; any value < 0.5 is considered a hallucination. The final hallucination rate is the percentage of articles with a hallucinated summary [90].
3.1.2 Workflow Diagram
Clinical-Grade Safety Framework
A framework published in npj Digital Medicine provides a more granular approach suitable for high-stakes research environments, classifying errors by both type and potential harm [91].
3.2.1 Protocol Summary
- Objective: Evaluate LLM safety and accuracy for technical text summarization through human-expert annotation.
- Dataset Construction: 450 consultation transcripts paired with LLM-generated clinical documentation, resulting in 12,999 clinician-annotated sentences [91].
- Error Taxonomy:
- Severity Assessment:
- Evaluation Process: Two clinician reviewers evaluate each sentence, with consolidation by a senior clinician in cases of discrepancy [91].
3.2.2 Safety Assessment Workflow
The Researcher's Toolkit: Key Reagents & Solutions
Table 3: Essential Resources for LLM Evaluation in Research Contexts
| Tool / Resource | Function | Application Context |
|---|---|---|
| Vectara Hallucination Leaderboard | Provides standardized benchmark of hallucination rates across LLMs [87] [90] | Model selection and baseline performance assessment |
| HHEM (Hallucination Evaluation Model) | Automated detection of factual inconsistencies in generated text [87] [90] | Continuous monitoring of LLM outputs in production systems |
| CREOLA Annotation Platform | Facilitates human expert evaluation and labeling of LLM outputs [91] | High-stakes validation for critical research applications |
| RAG (Retrieval-Augmented Generation) | Grounds LLM responses in verified external knowledge bases [89] [92] [93] | Reducing hallucinations in domain-specific literature review |
| MMLU (Massive Multitask Language Understanding) | Measures broad knowledge and problem-solving abilities [88] | General capability assessment across STEM and humanities |
Emerging Mitigation Strategies
Current research indicates that hallucinations are not merely a technical bug but a systemic incentive problem, where training objectives reward confident guessing over calibrated uncertainty [92]. Emerging mitigation strategies showing promise in 2025 research include:
- Reward Models for Calibrated Uncertainty: New reinforcement learning approaches that penalize both over- and under-confidence, aligning model certainty with actual correctness [92].
- Fine-Tuning on Hallucination-Focused Datasets: Targeted preference tuning using synthetic examples of hard-to-hallucinate content, shown to reduce hallucination rates by 90-96% without sacrificing quality [92].
- Retrieval-Augmented Generation with Span-Level Verification: Enhanced RAG systems that match each generated claim against retrieved evidence at the span level, flagging unsupported assertions [92].
- Factuality-Based Reranking: Generating multiple candidate responses then selecting the most factual using lightweight verification metrics [92].
- Internal Concept Steering: Modifying the model's internal "concept vectors" to learn when not to answer, turning refusal into a learned policy [92].
For the chemical life cycle assessment and drug development communities, where factual accuracy is non-negotiable, the systematic evaluation of LLM performance is a critical prerequisite for adoption. The frameworks and data presented herein provide a foundation for researchers to make informed decisions about model selection, implement appropriate safeguards through techniques like RAG, and establish continuous monitoring protocols. As the field evolves toward better-calibrated uncertainty and more reliable factuality, these assessment methodologies will serve as essential tools for harnessing LLM capabilities while maintaining scientific rigor.
Evaluating Explanation Quality and Adherence to Scientific Instructions
In the domain of chemical life cycle assessment (LCA), the application of large language models (LLMs) presents a unique opportunity to automate and enhance data retrieval and interpretation processes. The accuracy of LCA is fundamentally dependent on reliable life cycle inventory (LCI) data, the acquisition of which is traditionally time-consuming, often requiring extensive literature reviews or access to restricted databases [22]. LLMs, particularly when fine-tuned for specialized domains, offer a promising pathway to streamline this workflow. However, the utility of an LLM's output is contingent upon two critical factors: the quality of its explanations and its strict adherence to scientific instructions and protocols. This document outlines detailed application notes and experimental protocols for the rigorous evaluation of LLMs on these fronts within chemical LCA research. The framework presented is adapted from methodologies demonstrated in successful implementations, such as the "Sustain-LLaMA" model, which has been used for retrieving LCI and environmental impact data from scientific literature [22].
Background and Significance
The integration of LLMs into chemical LCA research can significantly accelerate sustainability assessments for chemicals and plastics, guiding industries toward more sustainable practices [22]. General-purpose LLMs, while versatile, often require specialized adaptation—through fine-tuning and prompt engineering—to perform optimally in specialized scientific domains [94]. A key challenge lies in the fact that these models can generate outputs that are seemingly plausible but scientifically inaccurate or inadequately explained. Therefore, establishing a standardized evaluation framework is paramount. This aligns with broader efforts in other data-intensive fields, such as clinical medicine, where expert consensuses are emerging to create retrospective evaluation frameworks for LLM applications, ensuring their safe and effective use [95]. The protocols described herein aim to provide a similarly structured approach for the chemical LCA domain.
Quantitative Evaluation Metrics and Data Presentation
A multi-faceted quantitative assessment is essential for benchmarking LLM performance. The following metrics should be collected and analyzed.
Table 1: Core Quantitative Metrics for Explanation Quality Evaluation
| Metric Category | Specific Metric | Definition / Calculation Method | Target Benchmark (Example) |
|---|---|---|---|
| Factual Accuracy | F1 Score | Harmonic mean of precision and recall for extracted data points vs. human-annotated ground truth [22]. | ≥ 0.82 (as achieved in LCI Q&A tasks) [22] |
| Exact Match (EM) | Percentage of outputs where all extracted data exactly matches the reference. | Case-dependent | |
| Data Reliability | Hallucination Rate | Percentage of generated statements or data points that are unsupported by the source text. | Minimize |
| Instruction Adherence | Protocol Compliance Score | Score (e.g., 0-100%) reflecting how completely an LLM follows a detailed experimental or reporting protocol. | Maximize |
| Task Performance | Classification Accuracy | Accuracy in identifying relevant scientific documents for a given LCA query [22]. | ≥ 0.85 [22] |
Table 2: Metrics for Specific LCA Workflow Stages
| LCA Workflow Stage | Primary Evaluation Metric | Secondary Metrics |
|---|---|---|
| Literature Identification | Document Classification Accuracy [22] | Precision, Recall |
| Data Extraction (LCI) | F1 Score for Q&A [22] | Exact Match, Hallucination Rate |
| Impact Interpretation | Protocol Compliance Score | Factual Accuracy, Reference Completeness |
Experimental Protocols for Evaluation
Protocol 1: Fine-Tuning for Domain-Specific LCA Knowledge
This protocol is based on the methodology used to develop "Sustain-LLaMA," which involved retraining a base LLaMA-2-7B model [22].
- Objective: To inject specialized chemical LCA knowledge into a base LLM, enhancing its performance on domain-specific tasks.
- Materials and Inputs:
- Base LLM: A foundational model such as LLaMA-2-7B [22].
- Training Corpus: A curated collection of scientific literature, textbook chapters, and existing LCA database entries focused on chemical synthesis, material properties, and environmental impact studies.
- Computational Resources: High-performance computing clusters with multiple GPUs (e.g., NVIDIA A100 or H100) are typically required for model pretraining.
- Procedure:
- Step 1: Data Curation. Assemble a comprehensive text corpus from reliable sources (e.g., ACS Publications, Elsevier, LCA databases). Clean and preprocess the text.
- Step 2: Continued Pretraining. Using the curated corpus, perform continued pretraining (or domain-adaptive pretraining) on the base LLM. This step does not use labeled question-answer pairs but rather allows the model to learn the language and concepts of the LCA domain by predicting the next token in the corpus.
- Step 3: Validation. Evaluate the model's language modeling performance (e.g., perplexity) on a held-out validation set from the LCA corpus.
- Expected Output: A domain-adapted LLM (e.g., Sustain-LLaMA) with a foundational understanding of chemical LCA terminology and concepts.
Protocol 2: Evaluating LCI Data Extraction via Question Answering
This protocol assesses the LLM's ability to accurately extract specific LCI data points from scientific text.
- Objective: To quantify the accuracy and reliability of an LLM in extracting precise numerical values and categorical data from relevant literature.
- Materials and Inputs:
- Model Under Test: The fine-tuned LLM from Protocol 1.
- Evaluation Dataset: A benchmark dataset of scientific text passages (e.g., from literature on methanol production or plastic packaging EoL treatment) with human-annotated questions and ground-truth answers [22].
- Framework: A Retrieval Augmented Generation (RAG) framework is recommended to provide the model with relevant source text chunks, mitigating hallucination.
- Procedure:
- Step 1: Query Formulation. For each text passage in the evaluation dataset, formulate specific, fact-seeking questions (e.g., "What is the global warming potential value for methanol production from natural gas?").
- Step 2: Model Inference. Input the question and the relevant source text passage into the LLM and generate an answer.
- Step 3: Metric Calculation. Compare the LLM's generated answers to the human-annotated ground truth. Calculate the F1 score, Exact Match, and Hallucination Rate for the entire dataset.
- Expected Output: Quantitative performance metrics (as listed in Table 1) that benchmark the LLM's data extraction capability against known standards and alternative models (e.g., GPT-4o, non-fine-tuned base models) [22].
Protocol 3: Auditing Adherence to Scientific Instructions
This protocol evaluates how well an LLM follows complex, multi-step scientific instructions.
- Objective: To measure an LLM's ability to comply with structured reporting guidelines and methodological protocols.
- Materials and Inputs:
- Model Under Test: The LLM to be evaluated.
- Instruction Set: A predefined set of scientific reporting instructions (e.g., "Summarize the following study. Your summary must include: 1. The goal of the study, 2. The system boundary, 3. The key LCI data, and 4. At least three environmental impact categories discussed.").
- Source Text: A collection of LCA research papers.
- Procedure:
- Step 1: Prompting. Provide the LLM with the source text and the detailed instruction set.
- Step 2: Output Generation. Collect the LLM's generated summary or report.
- Step 3: Compliance Scoring. Have domain experts or a validated scoring rubric assess the output. The "Protocol Compliance Score" is the percentage of required instruction items that were fully and correctly addressed in the output.
- Expected Output: A quantitative compliance score for each model and task, allowing for comparison of different models or prompting strategies on their ability to follow scientific rigor.
Workflow Visualization
The following diagram illustrates the end-to-end evaluation workflow for an LLM in chemical LCA research, integrating the protocols described above.
The Scientist's Toolkit: Research Reagent Solutions
The following table details key computational and data "reagents" required for implementing the evaluation protocols.
Table 3: Essential Research Reagents and Resources for LLM Evaluation in Chemical LCA
| Item Name | Type | Function / Application | Exemplars / Notes |
|---|---|---|---|
| Base LLM | Software Model | Foundational model that is adapted for the LCA domain via fine-tuning. | LLaMA-2-7B [22], GPT-series models [94]. |
| Domain Corpus | Dataset | A curated collection of text used to inject domain-specific knowledge into the base LLM during fine-tuning. | Scientific literature on chemical production, plastic EoL treatment, and environmental impacts [22]. |
| Evaluation Benchmark | Dataset | A labeled dataset with questions and ground-truth answers for quantitatively testing the LLM's performance. | Custom datasets for specific chemicals (e.g., methanol production) or processes (e.g., plastic packaging EoL) [22]. |
| RAG Framework | Software Method | Enhances the LLM by retrieving relevant text chunks from a knowledge base, improving factuality and reducing hallucinations [22]. | Used in the Sustain-LLaMA Q&A model to achieve high F1 scores [22]. |
| High-Performance Computing (HPC) Cluster | Hardware | Provides the necessary computational power for training and fine-tuning large models, which is computationally intensive. | GPU clusters (e.g., with NVIDIA A100/V100) are standard for this work. |
The integration of Large Language Models (LLMs) into chemical life cycle assessment and drug discovery represents a significant paradigm shift, offering novel methodologies for understanding disease mechanisms, facilitating de novo drug discovery, and optimizing research workflows [44] [96]. LLMs are advanced AI systems trained on at least one billion parameters, enabling them to understand, generate, and respond to human-like text and code [97]. Their application ranges from target identification and preclinical research to clinical trial analysis and regulatory compliance [44] [96]. For researchers, scientists, and drug development professionals, the decision between open-source and closed-source models is not merely technical but strategic, influencing data sovereignty, innovation velocity, and practical utility within the research lifecycle.
Core Conceptual Differences and Research Implications
Defining the Paradigms
Open-Source LLMs are characterized by public accessibility to their architecture, weights, and often training data, fostering a collaborative, transparent approach to development [97] [98]. Examples include LLaMA 3 (Meta), Gemma 2 (Google), and Mixtral (Mistral AI) [99]. This openness allows researchers to inspect, modify, and customize models for specific scientific domains.
Closed-Source LLMs are proprietary systems where access is restricted and typically provided via API. Their internal workings are not publicly available, making them "black boxes" [97] [100]. Prominent examples are GPT-4 and GPT-4 Turbo (OpenAI), Claude 3 (Anthropic), and Gemini 1.5 (Google) [98]. The development and updates are centrally controlled by the vendor.
Strategic Trade-Offs for Research
The choice between these paradigms involves fundamental trade-offs that directly impact research capabilities, as summarized in the table below.
Table 1: Core Strategic Trade-offs Between Open and Closed LLMs in Research
| Aspect | Open-Source LLMs | Closed-Source LLMs |
|---|---|---|
| Transparency & Auditability | Full visibility into model architecture and training data allows researchers to audit for biases and understand limitations [101] [98]. | "Black box" nature; limited visibility into data sources or reasoning processes, raising concerns about inherent biases [100] [102]. |
| Customization & Control | Can be fine-tuned with domain-specific data (e.g., chemical libraries, research papers) for highly specialized tasks [101] [99]. | Customization is severely limited, often restricted to prompt engineering and vendor-provided fine-tuning APIs [100] [98]. |
| Data Privacy & Security | Can be deployed on private infrastructure, ensuring sensitive research data never leaves the institution's control [101] [99]. | Data must be sent to the vendor's server, posing potential risks for confidential or proprietary research information [100] [102]. |
| Cost Structure | Free licensing fees; costs are primarily associated with in-house computational resources and expertise [97] [101]. | Typically a usage-based or subscription fee (cost per token/request), which can become significant at scale [97] [98]. |
| Innovation Speed | Community-driven, fast-paced experimentation and rapid iteration of specialized variants [97] [102]. | Reliant on the vendor's roadmap; updates and new features are rolled out uniformly to all users [100] [98]. |
| Support & Reliability | Relies on community forums and documentation; may lack guaranteed Service Level Agreements (SLAs) [101] [98]. | Backed by professional support teams, comprehensive documentation, and formal SLAs [102] [98]. |
Quantitative Comparison for Research Applications
For research institutions, the financial and performance characteristics of LLMs are critical factors in resource allocation and project planning.
Table 2: Quantitative Comparison of Selected Open-Source and Closed-Source LLMs (Data as of 2024-2025)
| Model Name | Type | Context Window (Tokens) | Parameter Size | Exemplary Cost (Input/Output) | Key Research Strengths |
|---|---|---|---|---|---|
| LLaMA 3 (70B) [99] | Open | 128K | 70 Billion | ~$0.60 / ~$0.70 (per million tokens) [97] | Strong all-around performance, optimized for dialogue and coding tasks. |
| Mixtral 8x22B [99] | Open | 64K | 141B (39B active) | Free (self-hosted) | Multilingual proficiency; strong in mathematics and coding [99]. |
| Gemma 2 (27B) [99] | Open | 8K | 27 Billion | Free (self-hosted) | High performance for its size, efficient inference on various hardware. |
| GPT-4 [97] | Closed | 128K | Not Disclosed | ~$10.00 / ~$30.00 (per million tokens) [97] | Top-tier reasoning, strong performance on professional and academic benchmarks. |
| Claude 3 [98] | Closed | 200K | Not Disclosed | Varies by version | Large context window, built with a focus on safety and reduced harmful outputs. |
| Gemini 1.5 Pro [44] | Closed | ~1M | Not Disclosed | Varies by version | Massive context window, multimodal capabilities. |
Experimental Protocols for LLM Evaluation in Research
Implementing a rigorous, evidence-based evaluation framework is essential for selecting the optimal LLM for specific research and development tasks.
Protocol 1: Benchmarking Domain-Specific Task Performance
This protocol provides a methodology for quantitatively comparing the performance of different LLMs on specialized research tasks.
Diagram 1: Task Performance Evaluation Workflow
Objective: To quantitatively compare the performance of shortlisted open-source and closed-source LLMs on specialized tasks relevant to chemical lifecycle assessment.
Materials & Reagents:
- Candidate LLMs: Pre-selected open-source (e.g., LLaMA 3, Gemma 2) and closed-source (e.g., GPT-4, Claude 3) models.
- Evaluation Dataset: A curated, gold-standard dataset of prompts and expected outputs. This should be held-out and not used for training.
- Computational Infrastructure: Sufficient GPU/CPU resources for running open-source models and API access keys for closed-source models.
- Evaluation Rubric: A standardized scoring sheet for human experts.
Methodology:
- Task Definition: Identify 3-5 critical tasks (e.g., "Named Entity Recognition for chemical compounds from text," "Summarization of toxicology reports," "Generation of NONMEM code snippets" [44]).
- Dataset Curation: For each task, compile a minimum of 50 test prompts with validated reference answers or code.
- Prompt Execution: Submit each prompt in the test dataset to all candidate LLMs using a standardized, zero-shot or few-shot prompt template to ensure fairness.
- Output Collection: Systematically record all model outputs for blinded analysis.
- Expert Evaluation: Have domain experts (e.g., clinical pharmacologists, computational biologists) score the blinded outputs based on accuracy, relevance, coherence, and potential for hallucination [44] [101].
- Statistical Analysis: Aggregate scores and perform statistical testing (e.g., ANOVA) to identify significant performance differences between models. Report results with mean scores and standard deviations.
Protocol 2: Data Security and Privacy Compliance Testing
This protocol assesses the data handling characteristics of LLMs, a critical factor for research involving confidential or proprietary information.
Objective: To evaluate the data privacy risks associated with using different LLM platforms, specifically for sensitive research data.
Materials & Reagents:
- Test Data: Synthetic datasets designed to mimic the structure and sensitivity of real proprietary research data (e.g., chemical structures, assay results).
- Network Monitoring Tools: Software to monitor data traffic (e.g., Wireshark).
- LLM Platforms: On-premises deployment of an open-source model (e.g., LLaMA 3) and API-based access to a closed-source model (e.g., GPT-4).
Methodology:
- Deployment Configuration: Deploy the open-source model on a secure, air-gapped institutional server. Configure API access for the closed-source model.
- Data Transmission Test: Use network monitoring tools to confirm that queries to the closed-source model are transmitted over the internet to the vendor's servers. Confirm that queries to the on-premises model remain within the local network.
- Data Retention Interrogation: Submit specific test data strings to the closed-source model via its API. In subsequent sessions, prompt the model to reproduce the previously submitted test data to check for potential memorization and unintended data leakage [101].
- Compliance Assessment: Map the data flow findings against institutional data governance policies and regulatory requirements (e.g., GDPR, HIPAA). Document which model deployment method is compliant for handling different classes of sensitive data.
The Scientist's Toolkit: Essential Research Reagent Solutions
The effective application of LLMs in research requires a suite of software and platform "reagents." The following table details key solutions and their functions.
Table 3: Essential "Research Reagent Solutions" for LLM Implementation
| Tool / Solution Name | Primary Function | Relevance to Research Lifecycle |
|---|---|---|
| Hugging Face Transformers [99] | A Python library providing APIs and tools to download, train, and run state-of-the-art pre-trained open-source models. | The primary platform for accessing, experimenting with, and fine-tuning thousands of open-source LLMs for domain-specific tasks. |
| Retrieval-Augmented Generation (RAG) [44] | A technique that grounds an LLM's responses by retrieving information from a designated knowledge base (e.g., internal research documents). | Critical for reducing model hallucination and ensuring outputs are based on trusted, proprietary data sources like internal compound libraries or research papers. |
| Ollama / Llama.cpp [99] | Tools optimized for running open-source LLMs locally on consumer-grade hardware, often using quantization techniques. | Enables researchers to prototype and run smaller LLMs efficiently on local machines (even laptops) without requiring extensive GPU infrastructure. |
| TensorRT-LLM / vLLM [99] | High-performance inference engines for deploying and serving open-source LLMs in production environments. | Used for optimizing the speed and throughput of self-hosted models once they move from prototyping to production-level use in research workflows. |
| Open LLM Leaderboard (Hugging Face) [100] | A real-time benchmark comparing the performance of open-source models across reasoning, generation, and multilingual tasks. | A key resource for researchers to quickly identify and shortlist the most performant open-source models for their evaluation protocols. |
Integrated Decision Framework for Model Selection
The following decision matrix synthesizes the comparative findings into an actionable workflow for researchers. It emphasizes that the optimal choice is contingent on specific project requirements regarding data, tasks, and resources.
Diagram 2: LLM Selection Decision Matrix
As visualized in the decision matrix, the choice is rarely binary. Sophisticated research organizations are increasingly adopting hybrid architectures [100]. This approach leverages closed-source models for general, low-risk tasks (e.g., literature review, initial email drafting) while reserving fine-tuned open-source models for sensitive, high-value, or domain-specific applications (e.g., analyzing confidential experimental data, generating specialized code for pharmacometric analysis [44]). This modular strategy provides the flexibility to optimize for both performance and control within a single research ecosystem.
The integration of large language models (LLMs) into chemical life cycle assessment (LCA) research represents a paradigm shift, offering potential breakthroughs in efficiency and scalability for drug development professionals. However, this integration introduces a critical challenge: determining when AI-generated LCA insights are sufficiently reliable for research and decision-making. Recent expert-grounded benchmarks reveal that 37% of LLM responses in LCA contexts contain inaccurate or misleading information, with some models producing hallucinated citations at rates up to 40% [41]. This application note establishes protocols for critically evaluating LLM benchmark performance to determine appropriate levels of trust in AI-generated LCA insights, with specific consideration for pharmaceutical and chemical research contexts.
Quantitative Benchmarking Landscape
Performance Metrics Across Domains
Comprehensive evaluation requires understanding how LLMs perform across standardized metrics. The table below synthesizes key benchmark results from multiple domains relevant to LCA research.
Table 1: LLM Performance Across Validation Requirements in Specialized Domains
| Domain | Model | Comprehensiveness | Correctness | Usefulness | Explainability | Safety |
|---|---|---|---|---|---|---|
| Longevity Interventions [103] | GPT-4o | 0.85 ± 0.06 | 0.73 ± 0.02 | 0.89 ± 0.03 | 0.94 ± 0.04 | 0.99 ± 0.01 |
| Longevity Interventions [103] | Llama 3.2 3B | 0.28 ± 0.08 | 0.52 ± 0.08 | 0.44 ± 0.08 | 0.54 ± 0.11 | 0.89 ± 0.05 |
| Longevity Interventions [103] | Llama3 Med42 8B | 0.20 ± 0.09 | 0.61 ± 0.06 | 0.48 ± 0.10 | 0.53 ± 0.13 | 0.91 ± 0.02 |
| LCA-Specific QA [83] | RAG-Enhanced LLM | BERTScore: 0.85 | - | - | - | - |
| LCA Data Retrieval [83] | Text2SQL-Enhanced | Execution Accuracy: 0.97 | - | - | - | - |
LCA-Specific Performance Indicators
In dedicated LCA benchmarks, seventeen experienced practitioners reviewed 168 AI-generated answers across 22 LCA-related tasks, providing critical insights into domain-specific performance [41]:
- Accuracy and Explanation Quality: Generally rated "average" to "good" across many models, including smaller parameter models
- Format Adherence: Typically rated favorably across model types
- Open vs. Closed Weight Models: No clear distinction, with open-weight models often competing at par with closed-weight models on accuracy and explanation quality
- Hallucination Rates: Varied significantly between models, with citation hallucination reaching 40% in some cases
Experimental Protocols for Benchmark Evaluation
Protocol 1: Expert-Grounded LCA Benchmarking
Purpose: To establish ground-truthed evaluation of LLM performance on LCA-specific tasks where no absolute ground truth exists.
Methodology:
- Task Selection: Identify 22 representative LCA tasks spanning goal definition, inventory analysis, impact assessment, and interpretation [41]
- Model Response Generation: Generate responses across 11 general-purpose LLMs (commercial and open-source) using baseline prompting without proprietary UI augmentations
- Expert Review: Engage 17 experienced LCA practitioners to assess outputs against predefined criteria
- Evaluation Criteria: Score responses on scientific accuracy, explanation quality, robustness, verifiability, and adherence to instructions
- Statistical Analysis: Calculate agreement rates and identify significant performance patterns
Key Insights: This approach addresses the fundamental challenge in LCA benchmarking: the field itself lacks well-defined ground truth, with replication studies often yielding widely varying results due to subjective methodological choices [41].
Protocol 2: Multi-Dimensional Validation Requirement Assessment
Purpose: To evaluate LLM performance across comprehensive validation axes critical for scientific applications.
Methodology:
- Test Item Development: Create 25 synthetic medical profiles (expandable to 1000 test cases through modular combination) for longevity intervention recommendations [103]
- Validation Framework: Implement five key requirements:
- Comprehensiveness: Coverage of relevant considerations
- Correctness: Factual and scientific accuracy
- Usefulness: Practical applicability to the problem
- Explainability: Transparency of reasoning process
- Safety: Risk mitigation in recommendations
- Evaluation System: Implement LLM-as-a-judge paradigm with clinician-validated ground truths
- RAG Assessment: Compare performance with and without retrieval-augmented generation
- Bias Testing: Evaluate performance across different age groups and comorbidity profiles
Key Insights: This protocol reveals that models typically perform well on safety but struggle with comprehensiveness, and that RAG effects are inconsistent across model types [103].
Protocol 3: Contamination-Resistant Benchmarking
Purpose: To address data contamination issues that undermine benchmark validity through memorization rather than reasoning.
Methodology:
- Dynamic Test Development: Implement frequently updated benchmarks (e.g., LiveBench, LiveCodeBench) with questions sourced from recent publications and competitions [104]
- Novel Problem Generation: Create previously unpublished questions that test genuine reasoning capabilities
- Memorization Detection: Track performance differentials between established and novel benchmarks
- Proprietary Test Sets: Maintain organization-specific evaluation datasets separate from public training data
- Version Control: Implement rigorous dataset versioning to track performance over time while minimizing leakage
Key Insights: Research shows some model families experience up to 13% accuracy drops on contamination-free tests compared to original benchmarks, revealing memorization rather than genuine capability [104].
Implementation Workflow
The following diagram illustrates the integrated workflow for evaluating and implementing LLMs in LCA research, incorporating domain specialization and validation techniques.
Diagram 1: LLM Evaluation and Implementation Workflow for LCA Research
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Resources for LLM Evaluation in Chemical LCA Research
| Tool Category | Specific Solution | Function in LLM Evaluation |
|---|---|---|
| Benchmark Platforms | Zooniverse [41] | Crowd science data platform for expert review collection |
| Evaluation Frameworks | BioChatter [103] | Open-source framework for biomedical LLM benchmarking |
| Domain-Specific LLMs | Chat-LCA [83] | RAG-enhanced LLM specialized for LCA domain knowledge |
| Retrieval Systems | RAGAS [104] | Specialized metrics for retrieval-augmented generation systems |
| Contamination-Resistant Benchmarks | LiveBench, LiveCodeBench [104] | Frequently updated benchmarks to prevent data memorization |
| Multi-Dimensional Evaluators | LLM-as-a-Judge [105] | Automated evaluation using advanced LLMs as judges |
| Text-to-SQL Systems | Chain of Thought + Chain of Code [83] | Converts natural language to SQL queries for LCI database retrieval |
Interpretation Guidelines and Decision Framework
Trust Thresholds for Different Applications
The appropriate level of trust in AI-generated LCA insights varies significantly by application context:
- High Trust Scenarios: Format adherence tasks, template-based report generation, and LCI database retrieval with Text2SQL enhancement (EX: 0.97) [83]
- Medium Trust Scenarios: Initial literature summarization with RAG verification (BERTScore: 0.85) and social LCA assessments with 50% human agreement rates [106] [83]
- Low Trust Scenarios: Unverified citation generation, novel methodological recommendations, and complex multi-stakeholder trade-off analyses without human oversight
Critical Risk Mitigation Strategies
- Hallucination Reduction: Implement RAG systems to ground responses in verified knowledge bases, reducing hallucination rates [41] [83]
- Human-in-the-Loop Protocols: Maintain expert oversight for high-stakes decisions, particularly where tacit knowledge or nuanced stakeholder perspectives are required [106]
- Perspective Alignment: Explicitly define assessment perspectives in system instructions to minimize variability in social and environmental impact evaluations [106]
Interpreting LLM benchmark results for chemical LCA applications requires a nuanced, multi-dimensional approach that acknowledges both the capabilities and limitations of current AI systems. By implementing the protocols and frameworks outlined in this application note, drug development professionals can establish scientifically rigorous practices for determining when to trust AI-generated LCA insights. The evolving landscape of LLM evaluation necessitates continuous reassessment of these trust boundaries as models advance and specialization techniques improve.
Conclusion
The integration of Large Language Models into Chemical Life Cycle Assessment presents a powerful, albeit nuanced, opportunity to redefine efficiency in drug discovery and development. While LLMs demonstrate significant potential to automate labor-intensive tasks, accelerate target identification, and scale LCA practices, their successful application hinges on a rigorous, human-centric approach. Key takeaways include the necessity of robust validation frameworks to combat hallucinations, the effectiveness of the 'biologist-in-the-loop' model for augmenting expertise, and a clear-eyed awareness of the technology's own environmental costs. For the future, the focus must be on developing standardized benchmarks, advancing grounding mechanisms like RAG, and fostering a culture of critical oversight. By doing so, researchers and clinicians can harness LLMs not as opaque oracles, but as reliable partners in building a more sustainable and accelerated path for biomedical innovation.
References
- 1. What Are Large Language Models (LLMs)? [https://www.ibm.com/think/topics/large-language-models]
- 2. Transformer Neural Networks: Ultimate 2025 Guide [https://swimm.io/learn/large-language-models/transformer-neural-networks-ultimate-2025-guide]
- 3. Transformer (deep learning) [https://en.wikipedia.org/wiki/Transformer_(deep_learning)]
- 4. Introduction to Large Language Models | Machine Learning [https://developers.google.com/machine-learning/resources/intro-llms]
- 5. LLM Tokenization: The Hidden Engine Behind Smarter AI [https://www.openxcell.com/blog/llm-tokenization/]
- 6. LLM Tokens Explained: The Ultimate Beginner's Guide (2025) [https://www.vibepanda.io/resources/blog/llm-tokens-explained-beginners-guide]
- 7. What is LLM Tokenization and Why Is It Important? [https://medium.com/thinking-sand/what-is-llm-tokenization-and-why-is-it-important-4eb5fbefb075]
- 8. Breaking Down the Modern LLM Training Pipeline - Blog [https://home.mlops.community/public/blogs/pretraining-breaking-down-the-modern-llm-training-pipeline]
- 9. What is LLM? - Large Language Models Explained [https://aws.amazon.com/what-is/large-language-model/]
- 10. Turning life cycle assessment insights into action - Ricardo [https://www.ricardo.com/en/news-and-insights/industry-insights/turning-life-cycle-assessment-insights-into-action-reducing-the-environmental-impact-of-chemical-products]
- 11. LLM Research Papers: The 2025 List (January to June) [https://magazine.sebastianraschka.com/p/llm-research-papers-2025-list-one]
- 12. Cultural Learning-Based Culture Adaptation of Language ... [https://arxiv.org/abs/2504.02953]
- 13. A Systematic Literature on Detecting Software Vulnerabilities... Review [https://arxiv.org/html/2507.22659v1]
- 14. September-October LC Net Newsletter published! [https://www.lifecycleinitiative.org/lc-net-september-october-2025-edition/]
- 15. We did the math on AI's energy footprint. Here's the story ... [https://www.technologyreview.com/2025/05/20/1116327/ai-energy-usage-climate-footprint-big-tech/]
- 16. Explained: Generative AI's environmental impact [https://news.mit.edu/2025/explained-generative-ai-environmental-impact-0117]
- 17. How Hungry is AI? Benchmarking Energy, Water, and ... [https://arxiv.org/abs/2505.09598]
- 18. Measuring the environmental impact of AI inference [https://cloud.google.com/blog/products/infrastructure/measuring-the-environmental-impact-of-ai-inference/]
- 19. Data Centers and Water Consumption | Article | EESI [https://www.eesi.org/articles/view/data-centers-and-water-consumption]
- 20. AI to drive 165% increase in data center power demand by ... [https://www.goldmansachs.com/insights/articles/ai-to-drive-165-increase-in-data-center-power-demand-by-2030]
- 21. AI's Cooling Problem: How Data Centers Are Transforming ... [https://www.eli.org/vibrant-environment-blog/ais-cooling-problem-how-data-centers-are-transforming-water-use]
- 22. A Large Language Model-based Framework to Retrieve ... [https://pubmed.ncbi.nlm.nih.gov/41100055/]
- 23. Why AI uses so much energy—and what we can do about it [https://iee.psu.edu/news/blog/why-ai-uses-so-much-energy-and-what-we-can-do-about-it]
- 24. 2025化学研究AI化趋势:8个AI智能体案例,架构师提前布局 [https://blog.csdn.net/2502_92021348/article/details/151657844]
- 25. 大模型在药物发现和研发中的应用综述:从疾病机理到临床试验 [https://blog.csdn.net/m0_59235245/article/details/145748060]
- 26. AI技术化工全场景智造探索和思考 [https://www.53ai.com/news/LargeLanguageModel/2025090559046.html]
- 27. 生命周期评价数据库有哪些 [https://www.fanruan.com/blog/article/17007/]
- 28. 大语言模型在药物开发中的应用前景:哈佛团队的深度分析 [https://www.xinfinite.net/t/topic/7597]
- 29. 09_LLM评估方法:如何判断模型性能的好坏 - 阿里云开发者社区 [https://developer.aliyun.com/article/1683951]
- 30. Machine Learning Models for Rapid Prediction of ... [https://www.sciencedirect.com/science/article/pii/S2950155525000485]
- 31. Integrating Artificial Intelligence into Life Cycle Assessment [https://link.springer.com/article/10.1007/s40831-025-01305-x]
- 32. 机器学习与人工智能驱动计算化学前沿进展:从精准预测反应 ... [https://www.forwardpathway.com/206737]
- 33. LLM 研究重新定义AI 在可持续系统保护中的作用 [https://developer.nvidia.cn/blog/llm-research-rewrites-the-role-of-ai-in-safeguarding-sustainable-systems/]
- 34. 什么是LLM 可观测性?全面指南 [https://www.elastic.co/cn/what-is/llm-observability]
- 35. AI和数据驱动医药开发:制度适用与成果保护 [https://www.zhonglun.com/research/articles/55124.html]
- 36. 大语言模型智能聊天机器人的能耗与碳足迹问题亟待关注 ... - 论文 [https://paper.sciencenet.cn/htmlpaper/2025/11/202511411325826142034.shtm]
- 37. AI赋能创新药研发:法律视角下的机遇与挑战 [https://meritsandtree.com/Content/2025/02-12/1805312450.html]
- 38. Automation of systematic reviews of biomedical literature [https://pmc.ncbi.nlm.nih.gov/articles/PMC11229257/]
- 39. A collaborative large language model for drug analysis [https://www.nature.com/articles/s41551-025-01471-z]
- 40. Automated product carbon footprints (PCF) creation with AI [https://www.pacemaker.ai/en/product-carbon-intelligence]
- 41. An Expert-grounded benchmark of General Purpose LLMs ... [https://arxiv.org/html/2510.19886v1]
- 42. Top 12 GHG Inventory Tool Options for 2025 [https://www.carbonpunk.ai/en/blog/top-12-ghg-inventory-tool-options-for-2025]
- 43. Augmenting data scientists and biologists through the ... [https://www.owkin.com/blogs-case-studies/augmenting-data-scientists-and-biologists-through-the-integration-of-llms-in-drug-discovery]
- 44. Large Language Models and Their Applications in Drug ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11984503/]
- 45. Circular Chemistry: How AI is Helping Close the Loop on ... [https://www.chemcopilot.com/blog/circular-chemistry-ai-helping]
- 46. Exploring the role of large language models in the scientific ... [https://www.nature.com/articles/s44387-025-00019-5]
- 47. Digital technologies for life cycle assessment: a review and ... [https://link.springer.com/article/10.1007/s11367-024-02409-4]
- 48. Emission Factor Recommendation for Life Cycle ... [https://pubmed.ncbi.nlm.nih.gov/40117648/]
- 49. MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented ... [https://aclanthology.org/2025.acl-long.131/]
- 50. A roadmap for large language models in chemical research [https://engineering.cmu.edu/news-events/news/2025/06/24-roadmap-for-llms.html]
- 51. SpiderGen:Towards Procedure Generation For Carbon Life ... [https://arxiv.org/html/2511.10684v1]
- 52. A Knowledge Graph Framework to Support Life Cycle ... [https://www.mdpi.com/2076-3417/15/1/175]
- 53. 32 examples of LLM applications in materials science and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12492978/]
- 54. Large language models for drug discovery and development [https://pmc.ncbi.nlm.nih.gov/articles/PMC12546459/]
- 55. Large Language Models for Automating Clinical Trial Criteria ... [https://medinform.jmir.org/2025/1/e71252]
- 56. Large language models in clinical trials - BMC Medicine [https://bmcmedicine.biomedcentral.com/articles/10.1186/s12916-025-04348-9]
- 57. Accelerating clinical evidence synthesis with large ... [https://www.nature.com/articles/s41746-025-01840-7]
- 58. Large language models in real-world clinical workflows [https://pmc.ncbi.nlm.nih.gov/articles/PMC12519456/]
- 59. Large language models for life cycle assessments [https://www.sciencedirect.com/science/article/abs/pii/S095965262402273X]
- 60. Team Provides a Roadmap for Large Language Models ... [https://www.cmu.edu/mcs/news-events/2025/0630-gomes-chemical-research-llm]
- 61. Domain-Specific Criteria for LLM Evaluation - Ghost [https://latitude-blog.ghost.io/blog/domain-specific-criteria-for-llm-evaluation/]
- 62. Ten Lessons of Building LLM Applications for Engineers [https://towardsdatascience.com/ten-lessons-of-building-llm-applications-for-engineers/]
- 63. LLM Evaluation Metrics: Benchmarks, Protocols & Best ... [https://dagshub.com/blog/llm-evaluation-metrics/]
- 64. Understanding and Navigating Knowledge Cutoffs in AI [https://www.conductor.com/academy/ai-knowledge-cutoff/]
- 65. How to Overcome LLM Knowledge Cutoff - RAG [https://www.linkedin.com/pulse/how-overcome-llm-knowledge-cutoff-rag-hagar-ibrahiem-4kebe]
- 66. 2026 Guide to Real‑Time Data Integration for Generative AI ... [https://www.cdata.com/blog/real-time-data-integration-for-generative-ai-llms]
- 67. 7 Real-Time Data Use Cases for LLM-Powered Applications [https://estuary.dev/blog/real-time-data-use-cases-llm-applications/]
- 68. Reconciling the contrasting narratives on ... [https://www.nature.com/articles/s41598-024-76682-6]
- 69. Entity Linking using LLMs for Automated Product Carbon ... [https://arxiv.org/html/2502.07418v1]
- 70. Life Cycle Assessment (LCA) – Everything you need to know [https://ecochain.com/blog/life-cycle-assessment-lca-guide/]
- 71. Integrating machine learning into life cycle assessment [https://journals.plos.org/climate/article?id=10.1371/journal.pclm.0000732]
- 72. Machine learning algorithms for supporting life cycle ... [https://www.sciencedirect.com/science/article/pii/S235255092500065X]
- 73. Landmark AI framework sets new standard for tackling ... [https://www.dlapiper.com/en/insights/publications/ai-outlook/2025/landmark-ai-framework-sets-new-standard-for-tackling-algorithmic-bias]
- 74. AI Ethical Guidelines [https://library.educause.edu/resources/2025/6/ai-ethical-guidelines]
- 75. Building a Responsible AI Framework: 5 Key Principles for ... [https://professional.dce.harvard.edu/blog/building-a-responsible-ai-framework-5-key-principles-for-organizations/]
- 76. Future Proofing LLMs Environmental Impact [https://datanorth.ai/blog/future-proofing-llms-environmental-impact]
- 77. Our contribution to a global environmental standard for AI [https://mistral.ai/news/our-contribution-to-a-global-environmental-standard-for-ai]
- 78. The Environmental Impact of Widespread LLM Adoption [https://randomwalk.ai/blog/the-environmental-impact-of-widespread-llm-adoption/]
- 79. Benchmarking Energy Efficiency of Large Language ... [https://arxiv.org/html/2509.08867v1]
- 80. How Much Energy Do LLMs Consume? Unveiling the ... [https://adasci.org/how-much-energy-do-llms-consume-unveiling-the-power-behind-ai/]
- 81. LLM Model Optimization Techniques and Frameworks [https://medium.com/@yugank.aman/llm-model-optimization-techniques-and-frameworks-e21d57744ca1]
- 82. Best practices for the sustainable use of AI and LLMs [https://greenplaces.com/articles/best-practices-for-sustainable-use-of-ai-and-llms/]
- 83. Intelligent application of large language model to life cycle ... [https://www.sciencedirect.com/science/article/abs/pii/S0959652625021262]
- 84. COLING-2025-Regulations-Challenge [https://coling2025regulations.thefin.ai/]
- 85. An interactive visualization approach for early design ... [https://www.sciencedirect.com/science/article/pii/S266616592300145X]
- 86. A comparative study of AI and human programming on ... [https://www.nature.com/articles/s41598-025-24658-5]
- 87. vectara/hallucination-leaderboard [https://github.com/vectara/hallucination-leaderboard]
- 88. ChatGPT Accuracy Rate (2025 Data) [https://explodingtopics.com/blog/chatgpt-accuracy]
- 89. AI Hallucination: Comparison of the Popular LLMs [https://research.aimultiple.com/ai-hallucination/]
- 90. Introducing the Next Generation of Vectara's Hallucination ... [https://www.vectara.com/blog/introducing-the-next-generation-of-vectaras-hallucination-leaderboard]
- 91. A framework to assess clinical safety and hallucination ... [https://www.nature.com/articles/s41746-025-01670-7]
- 92. LLM Hallucinations in 2025: How to Understand and ... [https://www.lakera.ai/blog/guide-to-hallucinations-in-large-language-models]
- 93. AI Hallucination: Definition, Causes, and Types Explained [https://www.glean.com/ai-glossary/ai-hallucination]
- 94. Implementing Large Language Models in Health Care [https://pmc.ncbi.nlm.nih.gov/articles/PMC12299950/]
- 95. 2025 Expert Consensus on Retrospective Evaluation of ... [https://www.sciencedirect.com/science/article/pii/S2667102625001044]
- 96. Large language models for drug discovery and development [https://www.sciencedirect.com/science/article/pii/S2666389925001941]
- 97. Open-Source LLMs vs Closed: Unbiased Guide for ... [https://hatchworks.com/blog/gen-ai/open-source-vs-closed-llms-guide/]
- 98. Open-Source LLMs vs Closed-Source LLMs [https://yellow.systems/blog/open-source-llms-vs-closed-source-llms]
- 99. Top 10 open source LLMs for 2025 [https://www.instaclustr.com/education/open-source-ai/top-10-open-source-llms-for-2025/]
- 100. Open vs. Closed LLMs in 2025: Strategic Tradeoffs for ... [https://medium.com/data-science-collective/open-vs-closed-llms-in-2025-strategic-tradeoffs-for-enterprise-ai-668af30bffa0]
- 101. Open source LLMs: Pros and Cons for your organization ... [https://www.searchunify.com/resource-center/blog/open-source-llms-pros-and-cons-for-your-organization-adoption]
- 102. Open-Source vs. Closed-Source LLMs: Weighing the Pros ... [https://lydonia.ai/open-source-vs-closed-source-llms-weighing-the-pros-and-cons/]
- 103. Benchmarking large language models for personalized ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12559286/]
- 104. LLM benchmarks in 2025: What they prove and what your ... [https://www.lxt.ai/blog/llm-benchmarks/]
- 105. 30 LLM evaluation benchmarks and how they work [https://www.evidentlyai.com/llm-guide/llm-benchmarks]
- 106. Towards AI-augmented sustainability assessments [https://link.springer.com/article/10.1007/s11367-025-02508-w]